
# 缓存基础常见面试题
# 为什么要用分布式缓存?
相关面试题:
- 为什么要用缓存?
- 本地缓存应该怎么做?
- 为什么要有分布式缓存?/ 为什么不直接用本地缓存?
- 多级缓存了解么?
# 缓存的基本思想
很多同学只知道缓存可以提高系统性能,减少请求相应时间。但是,不太清楚缓存的本质思想是什么。
缓存的基本思想其实很简单,就是我们非常熟悉的 **空间换时间**。不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。
其实,我们在学习使用缓存的时候,你会发现缓存的思想实际在操作系统或者其他地方都被大量用到。比如 CPU Cache 缓存的是内存数据,用于解决 CPU 处理速度和内存不匹配的问题;内存缓存的是硬盘数据,用于解决硬盘访问速度过慢的问题;操作系统在页表方案基础之上引入了快表,来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)。
我们知道,缓存中的数据通常存储于内存中,因此访问速度非常快。为了避免内存中的数据在重启或者宕机之后丢失,很多缓存中间件会利用磁盘做持久化。
也就是说,缓存相比于我们常用的关系型数据库(比如 MySQL)来说访问速度要快非常多。为了避免用户请求数据库中的数据速度过慢,可以在数据库之上增加一层缓存。
除了能够提高访问速度之外,缓存支持的并发量也要更大,有了缓存之后,数据库的压力也会随之变小。
# 缓存的分类
# 本地缓存
# 是什么
这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。
本地缓存位于应用内部,其最大的优点是应用存在于同一个进程内部,请求本地缓存的速度非常快,不存在额外的网络开销。
常见的单体架构图如下,我们使用 Nginx 来做负载均衡,部署两个相同的应用到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。

# 实现方案
1、JDK 自带的 HashMap 和 ConcurrentHashMap
一般不用
ConcurrentHashMap 可以看作是线程安全版本的 HashMap ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架 **至少要提供:过期时间、淘汰机制、命中率统计** 这三点。
2、 Ehcache 、 Guava Cache 、 Spring Cache 本地缓存框架
使用的比较多
Ehcache:相比于其他两者更加重量,不过Ehcache支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。Guava Cache和Spring Cache比较像。Guava相比于Spring Cache的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和ConcurrentHashMap的思想有异曲同工之妙。- 使用
Spring Cache的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
3、后起之秀 Caffeine
使用最多
相比于 Guava 来说 Caffeine 在各个方面比如性能要更加优秀,一般建议使用其来替代 Guava 。并且 Guava 和 Caffeine 的使用方式很像!
# 缺点
本地的缓存的优势非常明显:低依赖、轻量、简单、成本低。
但是,本地缓存存在下面这些缺陷:
- 本地缓存应用耦合,对分布式架构支持不友好:比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
- 本地缓存的容量受服务部署所在机器的限制明显:如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少。
# 分布式缓存
# 是什么
我们可以把分布式缓存(Distributed Cache)看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务。
分布式缓存脱离于应用独立存在,多个应用可直接的共同使用同一个分布式缓存服务。
如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的应用到服务器,两个服务使用同一个数据库和缓存。

使用分布式缓存之后,缓存服务可以部署在一台单独的服务器上,即使同一个相同的服务部署在多台机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
** 但是,软件系统设计中没有银弹,往往任何技术的引入都像是把双刃剑。** 你使用的方式得当,就能为系统带来很大的收益。否则,只是费了精力不讨好。
简单来说,为系统引入分布式缓存之后往往会带来下面这些问题:
- 系统复杂性增加:引入缓存之后,要维护缓存和数据库的数据一致性、维护热点缓存、保证缓存服务的高可用等等。
- 系统开发成本增加:引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。
# 实现方案:Redis
唯一真神:Redis!
# 多级缓存
这里只来简单聊聊 本地缓存 + 分布式缓存 的多级缓存方案。
这个时候估计有很多小伙伴就会问了:既然用了分布式缓存,为什么还要用本地缓存呢?
的确,一般情况下是不建议使用多级缓存的,这会增加维护负担(比如你需要保证一级缓存和二级缓存的数据一致性),并且,实际带来的提升效果对于绝大部分项目来说其实并不是很大。
多级缓存方案中,第一级缓存(L1)使用本地内存(比如 Caffeine),第二级缓存(L2)使用分布式缓存(比如 Redis)。读取缓存数据的时候,我们先从 L1 中读取,读取不到的时候再去 L2 读取。这样可以降低 L2 的压力,减少 L2 的读次数。并且,本地内存的访问速度是最快的,不存在什么网络开销。

# 常见的缓存更新策略有哪几种?
下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式即可!
# Cache Aside Pattern(旁路缓存模式)
平时使用比较多
# 是什么
Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,适合读请求比较多的场景。
Cache Aside Pattern 中 **服务端需要同时维系数据库(后文简称 db)和缓存(后文简称 cache)**,并且是以 db 的结果为准。
# 缓存读写步骤
写:
- 先更新 db
- 直接删除 cache

读:
- 先从 cache 中读取数据,读取到就直接返回
- cache 中读取不到的话,再从 db 中读取数据返回
- 再把从 db 中读取到的数据写入 cache 中

# 原理
问题:写数据时为什么删除 cache,而不是更新 cache?
仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
主要原因有两点:
- 对服务端资源造成浪费:删除 cache 更加直接,这是因为 cache 中存放的一些数据需要服务端经过大量的计算才能得出,会消耗服务端的资源,是一笔不小的开销。如果频繁修改 db,就能会导致需要频繁更新 cache,而 cache 中的数据可能都没有被访问到。
- 产生数据不一致问题:并发场景下,更新 cache 产生数据不一致性问题的概率会更大(后文会解释原因)。
追问:写数据时,为什么不先删除 cache ,再更新 db ?
答案:那肯定是不行的!因为这样可能 **会造成数据库(db)和缓存(Cache)数据不一致** 的问题。
举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。这个过程可以简单描述为:
请求 1 先把 cache 中的 A 数据删除;
请求 2 从 db 中读取数据;
请求 1 再把 db 中的 A 数据更新。
这就会导致请求 2 读取到的是旧值。
追问:写数据时,先更新 db,后删除 cache 就没有问题了么?
答案:理论上来说出现数据不一致性的概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。这个过程可以简单描述为:
请求 1 从 db 读数据 A;
请求 2 更新 db 中的数据 A(此时缓存中无数据 A ,故不用执行删除缓存操作 );
请求 1 将数据 A 写入 cache。
这就会导致 cache 中存放的其实是旧值。
# 缺点
缺陷 1:首次请求数据一定不在 cache 中
解决办法:将热点数据提前放入 cache 中
缺陷 2:写操作比较频繁的话,会导致 cache 中的数据频繁被删除,影响缓存命中率
解决办法:
数据库和缓存数据强一致场景:更新 db 的时候同样更新 cache,不过我们需要加一个锁 / 分布式锁来保证更新 cache 的时候不存在线程安全问题。
可以短暂地允许数据库和缓存数据不一致的场景:更新 db 的时候同样更新 cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
# Read/Write Through Pattern(读 / 写穿透模式)
在平时开发过程中非常少见
# 是什么
Read/Write Through Pattern 中服务端 **把 cache 视为主要数据存储,从中读 / 写数据;而 cache 服务负责将此数据读取和写入 db,从而减轻了应用程序的职责**。
这种缓存读写策略小伙伴们应该也发现了在平时开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供将 cache 数据写入 db 的功能。
# 缓存读写步骤
写(Write Through):
与旁路缓存模式的写步骤不同
先检查 cache 中是否存在要写入的数据:
若 cache 中不存在,则直接更新 db
若 cache 中存在,则先更新 cache;然后 cache 服务再更新 db

读(Read Through):
与旁路缓存模式的读步骤一样
先从 cache 中读取数据,读取到就直接返回
从 cache 中读取不到的话,再从 db 加载,最后写入 cache ,返回响应

# 原理
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
# 缺点
和 Cache Aside Pattern 一样, Read-Through Pattern 也存在首次请求数据一定不在 cache 的问题,可以将热点数据提前放入 cache 中。
# Write Behind Pattern(异步缓存写入模式)
在平时开发过程中也非常非常少见
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 db 的读写。
但是,两个又有很大的不同:Read/Write Through 是同步更新 cache 和 db,而 Write Behind 则是只更新 cache,不直接更新 db,而是改为异步批量的方式来更新 db。
很明显,这种方式对数据一致性带来了更大的挑战,比如 cache 数据可能还没异步更新 db 的话,cache 服务可能就就挂掉了。
这种策略在平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 Innodb Buffer Pool 机制都用到了这种策略。
Write Behind Pattern 下 db 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
# Redis 基础
# Redis 是什么
Redis(REmote DIctionary Server,远程词典服务器)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 Key-Value 键值对数据。
为了满足不同的业务场景,Redis 内置多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、发布 / 订阅、缓存淘汰、流技术等功能特性,提供了多种集群方案(主从模式、 Redis Sentinel 、 Redis Cluster )。
# Redis 怎么用
生产环境下,官方推荐使用 Linux 部署 Redis。
个人学习的话,可以自己本机安装 Redis 或者通过 Redis 官网提供的在线 Redis 环境(少部分命令无法使用)来实际体验 Redis。

techstacks.io 专门维护了一个使用 Redis 的热门站点列表 ,感兴趣的话可以看看。
# Redis 功能

分布式缓存,帮 MySQL 减负
![image-20231202180734903]()
MySQL 与 Redis 的对比:
- MySQL 是关系型数据库,Redis 是key-value数据库(NoSQL 的一种)
- MySQL 主要存储在磁盘,Redis 数据操作主要在内存
- Redis 在一些场景中明显优于 MySQL,例如计数器、排行榜等
- Redis 通常用于一些特定场景,需要与 MySQL 一起配合使用,两者并不是相互替换和竞争关系,而是共用和配合使用
内存存储和持久化(
RDB+AOF):Redis 支持异步将内存中的数据写到硬盘上,同时不影响继续服务![image-20231202180535935]()
高可用架构搭配:避免某台 Redis 挂了后,影响系统运行
- 单机
- 主从(replica)
- 哨兵(sentinel)
- 集群(cluster)
![image-20231202180648762]()
缓存穿透、击穿、雪崩
分布式锁:跨服务器加锁
消息队列平台:Reids提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。
通过 Reids 的队列功能做购买限制。比如到节假日或者推广期间,进行一些活动,对用户购买行为进行限制,限制今天只能购买几次商品或者一段时间内只能购买一次。
排行榜 + 点赞:Redis 提供的zset 数据类型能够快速实现这些复杂的排行榜。




# Redis 优势
- 读写性能极高
- 数据类型丰富:不仅支持key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
- 支持数据持久化:可将内存中的数据存入磁盘中,重启时再加载到内存使用
- 支持数据备份,即 master-slave 模式的数据备份
# Redis 迭代历史

5.0 版本是直接升级到6.0 版本,对于这个激进的升级,Redis 之父 antirez 表现得很有信心和兴奋,所以第一时间发文来阐述 6.0 的一些重大功能 "Redis 6.0.0 GA is out!"
随后 Redis 再接再厉,直接王炸Redis7.0---2023 年爆款。2022 年 4 月 27 日 Redis 正式发布了 7.0 更新(其实早在 2022 年 1 月 31 日,Redis 已经预发布了 7.0rc-1,经过社区的考验后,确认没重大 Bug 才会正式发布)
Redis 版本的命名规则:
- 版本号第二位如果是奇数,则为非稳定版本。如 2.7、2.9、3.1
- 版本号第二位如果是偶数,则为稳定版本。如 2.6、2.8、3.0、3.2
- 当前奇数版本就是下一个稳定版本的开发版本。如 2.9 版本是 3.0 版本的开发版本
# Redis7 新特性
可以从 redis 的 GitHub 的 releases 中查看当前版本的新特性,Redis7 的部分新特性总览:

Redis Functions:Redis 函数,一种新的通过服务端脚本扩展 Redis 的方式,函数与数据本身一起存储。简言之,redis 自己要去抢夺 Lua 脚本的饭碗,但是 Lua 已经稳定且普及,所以 Redis Functions没必要学
![image-20230802162230304]()
Client-eviction:客户端相关优化,能让更多 client 连接上
限制客户端内存使用,一旦 Redis 连接较多,再加上每个连接的内存占用都比较大的时候,Redis 总连接内存占用可能会达到 maxmemory 的上限,可以增加允许限制所有客户端的总内存使用量配置项,redis.config 中对应的配置项,有两种配置形式:
- 指定内存大小。例如 maxmemory-clients 1g
- 基于 maxmemory 的百分比。例如 maxmemory-clients 10%
![image-20230802162439869]()
Multi-part AOF:多 AOF 文件支持,AOF 文件由一个变成了多个,主要分为两种类型:基本文件 (base files)、增量文件 (incr files),请注意这些文件名称是复数形式说明每一类文件不仅仅只有一个。在此之外还引入了一个清单文件 (manifest) 用于跟踪文件以及文件的创建和应用顺序(恢复)。性能急剧上升,再也不用担心 AOFRW 异步读写时的运维痛点
![image-20230802163004405]()
config 命令增强:对于Config Set 和 Get 命令,支持在一次调用过程中传递多个配置参数。例如,现在我们可以在执行一次 Config Set 命令中更改多个参数: config set maxmemory 10000001 maxmemory-clients 50% port 6399
访问安全性增强 ACL V2:访问控制,在 redis.conf 配置文件中,protected-mode 默认为 yes,只有当你希望你的客户端在没有授权的情况下可以连接到 Redis server 的时候可以将 protected-mode 设置为 no
![image-20230802163118585]()
listpack 紧凑列表调整:listpack 是用来替代 ziplist 的新数据结构,在 7.0 版本已经没有 ziplist 的配置了(6.0 版本仅部分数据类型作为过渡阶段在使用),listpack 已经替换了 ziplist 类似 hash-max-ziplist-entries 的配置
RDB 保存时间调整:将持久化文件 RDB 的保存规则发生了改变,尤其是时间记录频度变化
命令新增和变动:
- Zset (有序集合) 增加 ZMPOP、BZMPOP、ZINTERCARD 等命令
- Set (集合) 增加 SINTERCARD 命令
- LIST (列表) 增加 LMPOP、BLMPOP ,从提供的键名列表中的第一个非空列表键中弹出一个或多个元素
性能资源利用率、安全、等改进:自身底层部分优化改动,Redis 核心在许多方面进行了重构和改进
- 主动碎片整理 V2:增强版主动碎片整理,配合 Jemalloc 版本更新,更快更智能,延时更低
- HyperLogLog 改进:在 Redis5.0 中,HyperLogLog 算法得到改进,优化了计数统计时的内存使用效率,7 更加优秀
- 更好的内存统计报告
- 如果不为了 API 向后兼容,我们将不再使用 slave 一词......(政治正确)




# 🌟Redis 为什么这么快?

回答思路:
- 内存存储:Redis 将数据存储在内存中,而直接访问内存的速度比访问磁盘的速度要快多个数量级;
- 优化的数据结构:Redis 提供了多种高效的数据结构,如字符串、哈希、列表、集合等,这些专门优化过的数据结构支持高效的读写操作;
- IO 多路复用 & 单线程模型:Redis 在架构上采用了 IO 多路复用 提高了资源利用率,通过 多线程非阻塞式 IO 来高效处理大量请求,并且只使用 单线程 执行读写命令,以避免上下文切换、锁竞争等问题。
下面这张图片总结的挺不错的,分享一下,出自 Why is Redis so fast?

# 内存存储
Redis 是一个内存数据库,不论读写操作都是在内存上完成的,而计算机访问内存比起磁盘读写要快出数个数量级。因此,相较其他需要从磁盘读取数据的传统数据库而言,Redis 的速度要快得多。
此外,由于数据直接从内存进行读写,而不必过多考虑如何将它们高效地保存到磁盘上(只有将数据以 RDB 的方式持久化时才会面对这个问题),这也使得 Redis 可以直接使用高效的底层数据结构。

# 底层数据结构
Redis 提供了多种高效的数据结构,如字符串、哈希、列表、集合等,这些专门优化过的数据结构支持高效的读写操作。
Redis 的高速很大程度上依赖于它丰富而高效的数据结构,而它们在底层实现上,都针对不同的使用场景进行了精心的设计和优化。

# 简单动态字符串(SDS)
字符串是 Redis 中最常用的数据结构,不过作者并没有使用 C 标准款的实现,而是自己实现了一套简单动态字符串(SDS)作为替代。
SDS 的特点是在保留 C 字符串特性的同时:
- 字段
len记录字符串长度,即已使用的字符串空间:实现了 O (1) 复杂度的strlen操作,并保证了二进制安全性; - 字段
alloc记录分配的内存大小,即总共可用的字符串空间:这使得修改字符串的时候可以通过计算,仅当空间不足时再扩展; - 字段
flags表示不同的 SDS 类型:Redis 在内部针对区分了多种 SDS 类型,Redis 会根据初始化的长度决定使用哪种类型的 SDS,有效的节省内存。 - 字段
buf[]实际存储字符串的数组

具体参见文章:[🌟String 的底层实现:SDS](#🌟String 的底层实现:SDS)
# 压缩列表(ZipList)
Redis 的 List、Hash、ZSet 个结构在数据量较小的情况下,会使用压缩列表保存数据。
压缩列表是一种结构类似数组的顺序结构。相比起传统的链表,它的节点由连续的内存块组成,每个节点都不需要指向前驱接点、后继节点以及存储数据的指针,而是直接记录到前一个元素和后一个元素的内存偏移量作为替代。
它会在列表头记录整个列表的占用字节数( zlbytes )、最后一个元素的偏移量( zltail )、元素数量( zllen ),从而支持快速访问列表的开头和末尾,以及快速确定列表的大小。

这种设计和布局使得 Redis 的压缩链表非常高效,能够在占用较少内存的情况下存储大量数据。
具体参见文章:zipList(压缩列表)
在 3.2 以后的版本版本,Redis 又逐渐引入了 quicklist 和 listpack 来替代跳表和压缩列表。
# 字典 / 哈希表
Redis 的哈希表与 Java 中相似,也是基于 key 得到的哈希值计算桶下标,再采用拉链法解决冲突,并在装载因子超过预定值时自动扩容。
扩容的特殊之处在于 **渐进式哈希**:
- 当扩容的时候,Redis 哈希表会基于扩容后的大小创建一张新的哈希表。
- 然后每次操作时都会先访问旧表,将访问到的桶中的链表转移到新表中,直到旧表的数据全部转移到新表以后,旧表会被回收,只留下新表。
它巧妙地避免的在一次操作中大批量的进行数据迁移,而是将其分摊到多次请求中。

# 跳表(SkipList)
跳表是一种基于链表实现的数据结构,它可以通过具有多层索引的方式来加速查找元素,每个元素在不同层次的链表中出现,从最底层链表开始,每个级别的链表包含前一个级别链表的子集。
相比起正常的列表,跳表在插入、删除和搜索时都具备 O(logn) 的复杂度,并且相比起树实现起来更加简单。
跳表在插入元素时采用随机分配层级的策略。即在确定了总层级后,每添加一个新的元素时会自动为其随机分配一个层级。这种随机性就解决了节点序号与层级间的固定关系问题。

跳表在查找元素时从最高层开始遍历,假设最高层为 k 索引,当我们确认元素大于 k 层的某个节点时,就进入 k-1 层,并从这个节点开始继续向前遍历,直到找到为止。

具体参见文章:🌟skipList(跳跃列表 / 跳表)
# IO 多路复用
Redis 基于 IO 多路复用(IO Multiplex)技术 实现了非阻塞式 IO,并发处理 socket 连接,提高了资源利用率和服务吞吐量。

Redis 会根据不同的操作系统的函数实现 IO 多路复用(一套网络事件库),包括 Solaris 中的 evport、Linux 中的 epoll 、Mac OS/FreeBSD 中的 kQueue 等操作系统函数…… 借助这些函数,即使只有单个线程,Redis 依然可以在事件循环中高效的响应并处理事件。

在这个模型中,它将会来自客户端的网络请求作为一个事件发布到队列中,然后线程将同步地获取事件并派发到不同的处理器,而处理器处理完毕后又会再发布另一个事件...... 整个主流程都由 Redis 的主线程在一个不间断的循环中完成,这就是事件循环(Event Loop)。
熟悉 Netty 的同学可能会觉得有点既视感,因为两者都可以认为基于反应器模式实现的 IO 模型,不过 Netty 可以有多个事件循环,并且还可以划分为 Boss 和 Worker 两类事件循环组,而 Redis 只有一个事件循环,并且在早期版本只有一个 IO 线程(也就是主线程本身)。
具体参见文章:一文搞懂 Redis 高性能之 IO 多路复用
# 单线程模型
Redis 的所有主线操作使用单线程模型,将网络 IO 以及指令读写全部交由一个线程来执行。
这样可以避免线程创建而导致的性能消耗,多线程上下文切换而引起的 CPU 开销,以及避免了多个线程之间的竞争问题,比如临界区资源的线程安全、锁的申请、释放以及死锁等问题。

随着请求规模的扩大,单个线程在网络 IO 上消耗的 CPU 时间越来越多,它逐渐成为了 Redis 的性能瓶颈。因此 Redis 6.0 正式引入了多线程来处理网络 IO。
在新的版本中,Redis 依然使用单个主线程来执行命令,但是使用多个线程来处理 IO 请求,主线程不再负责包括建立连接、读取数据和回写数据这些事情,而只是专注于执行命令。这个做法在保证单注线程设计的原有优点的情况下,又进一步提高了网络 IO 的处理效率。

Redis 的线程模型在不同版本有所不同:
- 2.0 版本:Redis 使用单个线程在事件循环中处理网络请求与执行操作指令,然后其他的后台线程负责释放 RDB/AOF 过程生成的临时文件资源与刷盘;
- 4.0 版本:Redis 添加了一个线程,用于异步执行
UNLINK(异步删除指定键)、FLUSHALL ASYNC(清空所有 DB)和FLUSHDB ASYNC(清空指定 DB)这些比较重的删除指令; - 6.0 版本:Redis 允许通过修改
io-threads和io-threads-do-reads修改 IO 线程数。
总的来说:
- 读写指令的单线程执行避免了锁竞争和上下文切换带来的额外性能开销;
- 异步完成文件操作与大 key 删除避免了主线程的长时间阻塞
- 多线程 IO 读写提高了网络 IO 性能
另外一提,读写指令要保持单线程,这个设计的理由是因为 CPU 对内存的操作已经足够高效,因此性能瓶颈不大可能来自于 CPU ,而主要来自于内存和网络 IO,因此执行命令的线程有一个足矣。
具体参见文章:[Redis 线程(IO)模型](#Redis 线程(IO)模型)
# Redis 高性能之 IO 多路复用
相信大家在面试过程中经常会被问到:“单线程的 Redis 为啥这么快?”
哈哈,反正我在面试时候经常会问候选人这个问题,这个问题其实是对 redis 内部机制的一个考察,可以牵扯出好多涉及底层深入原理的一些列问题。
回到问题本身,基本的回答就三点:
- 完全基于内存
- 优化的数据结构
- IO 多路复用
1、关于第 1 点比较好理解。Redis 绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,查找和操作的时间复杂度都是 O (1)。
2、关于第 2 点同样好理解。Redis 提供了多种高效的数据结构,如字符串、哈希、列表、集合等,这些专门优化过的数据结构支持高效的读写操作;
3、关于第 3 点 IO 多路复用,有些同学看到概念后感觉一头雾水,到底什么是 IO 多路复用?
本文从 IO 并发性能提升来整体思考,来逐步剖析 IO 多路复用的原理。
# 快速理解 IO 多路复用
# 多进程
对于并发情况,假如一个进程不行,那搞多个进程不就可以同时处理多个客户端连接了么?
多进程这种方式的确可以解决了服务器在同一时间能处理多个客户端连接请求的问题,但是仍存在一些缺点:
fork()等系统调用会使得进程上下文进行切换,效率较低- 进程创建的数量随着连接请求的增加而增加。比如 10w 个请求,就要 fork 10w 个进程,开销太大
- 进程与进程之间的地址空间是私有、独立的,使得进程之间的数据共享变得困难
# 多线程
线程是运行在进程上下文的逻辑流,一个进程可以包含多个线程,多个线程运行在同一进程上下文中,因此可共享这个进程地址空间的所有内容,解决了进程与进程之间通信难的问题。
同时,由于一个线程的上下文要比一个进程的上下文小得多,所以线程的上下文切换,要比进程的上下文切换效率高得多。
# 基于单进程的 IO 多路复用(select/poll/epoll)
简单理解就是:一个服务端进程可以同时处理多个套接字描述符(socket)。
- 多路:多个客户端连接(连接就是套接字描述符 socket )
- 复用:使用单进程就能够实现同时处理多个客户端的连接
以上是通过增加进程和线程的数量来并发处理多个套接字,免不了上下文切换的开销,而 IO 多路复用只需要一个进程就能够处理多个套接字,从而解决了上下文切换的问题。
其发展可以分 select->poll→epoll 三个阶段来描述。
# 简单理解 select/poll/epoll
按照以往惯例,还是联系一下我们日常中的现实场景,这样更助于大家理解。
举栗说明:领导分配员工开发任务,有些员工还没完成。如果领导要每个员工的工作都要验收 check,那在未完成的员工那里,只能阻塞等待,等待他完成之后,再去 check 下一位员工的任务,造成性能问题。
那如何解决这个问题呢?
# select
举栗说明:领导找个 Team Leader(后文简称 TL),负责代自己 check 每位员工的开发任务。TL 的做法是:遍历问各个员工 “完成了么?”,完成的待 CR check 无误后合并到 Git 分支,对于其他未完成的,休息一会儿后再去遍历....
这样存在什么问题呢?
- 这个 TL 存在能力短板问题,最多只能管理 1024 个员工
- 很多员工的任务没有完成,而且短时间内也完不成的话,TL 还是会不停地遍历问询,影响效率。
select 函数监视的文件描述符分 3 类,分别是 writefds 、 readfds 、和 exceptfds 。select 函数调用后会阻塞,直到有描述符就绪(有数据可写、可读、或者有 except),或者超时( timeout 指定等待时间,如果立即返回设为 null 即可),函数返回。当 select 函数返回后,可以通过遍历 fd_set ,来找到就绪的描述符。
int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset, const struct timeval *timeout); |
select 具有良好的跨平台支持,其缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在 Linux 上一般为 1024。
# poll
举栗说明:换一个能力更强的 New Team Leader(后文简称 NTL),可以管理更多的员工,这个 NTL 可以理解为 poll。
poll 函数:改变了文件描述符集合的描述方式,使用了 pollfd 结构而不是 select 的 fd_set 结构,使得 poll 支持的文件描述符集合限制远大于 select 的 1024。
intpoll(struct pollfd *fds, nfds_t nfds, int timeout); | |
typedef struct pollfd{ | |
int fd; // 需要被检测或选择的文件描述符 | |
short events; // 对文件描述符 fd 上感兴趣的事件 | |
short revents; // 文件描述符 fd 上当前实际发生的事件 | |
} pollfd_t; |
# epoll
举栗说明:在上一步 poll 方式的 NTL 基础上,改进一下 NTL 的办事方法:遍历一次所有员工,如果任务没有完成,告诉员工待完成之后,其应该做 xx 操作(制定一些列的流程规范)。这样 NTL 只需要定期 check 指定的关键节点就好了。这就是 epoll。
Linux 中提供的 epoll 相关函数如下:epoll 是 Linux 内核为处理大批量文件描述符而作了改进的 poll,是 Linux 下多路复用 IO 接口 select/poll 的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统 CPU 利用率。
int epoll_create(int size); | |
int epoll_ctl(int epfd, int op,int fd, struct epoll_event *event); | |
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); |
# 小结
select:就是轮询,在 Linux 上限制个数一般为 1024 个poll:解决了 select 的个数限制,但是依然是轮询epoll:解决了个数的限制,同时解决了轮询的方式
# IO 多路复用在 Redis 中的应用
# 小结
# 分布式缓存常见的技术选型方案
分布式缓存的话,比较老牌同时也是使用的比较多的还是 Memcached 和 Redis。不过,现在基本没有看过还有项目使用 Memcached 来做缓存,都是直接用 Redis。
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
另外,腾讯也开源了一款类似于 Redis 的分布式高性能 KV 存储数据库,基于知名的开源项目 RocksDB 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型,名为 Tendis。
关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:Redis vs Tendis:冷热混合存储版架构揭秘 ,可以简单参考一下。
从这个项目的 GitHub 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
# Redis 和 Memcached 的区别和共同点
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
共同点:
- 都基于内存,一般都用来当做缓存使用。
- 都有过期策略。
- 性能都非常高。
区别:
- Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
- Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。
- Redis 有灾难恢复机制。因为可以把缓存中的数据持久化到磁盘上。
- Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。
- Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。
- Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。(Redis 6.0 针对网络数据的读写引入了多线程)
- Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。
- Memcached 过期数据的删除策略只用了惰性删除,而 Redis 针对过期数据同时使用了惰性删除、定期删除。
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
# 为什么要用 Redis(或者缓存)?
1、高性能
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
这样有什么好处呢?那就是保证用户下一次再访问这些数据的时候,就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
2、高并发
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g),但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 Redis 的情况,Redis 集群的话会更高)。
QPS(Query Per Second):服务器每秒可以执行的查询次数;
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
# 常见的缓存读写策略
# Redis 应用
# Redis 除了做缓存,还能做什么?
分布式锁:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:分布式锁详解。
限流:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》。
消息队列:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
延时队列:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
分布式 Session:利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
复杂业务场景:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景,比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
…
# Redis 如何实现分布式锁?
指路 -> 分布式锁详解
# Redis 可以做消息队列么?
实际项目中也没见谁使用 Redis 来做消息队列,对于这部分知识点大家了解就好了。
先说结论:可以是可以,但不建议使用 Redis 来做消息队列,因为它不如专业的消息队列。
# List 实现方式
Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。
通过 RPUSH/LPOP 或者 LPUSH/RPOP 即可实现简易版消息队列:
# 生产者生产消息 | |
> RPUSH myList msg1 msg2 | |
(integer) 2 | |
> RPUSH myList msg3 | |
(integer) 3 | |
# 消费者消费消息 | |
> LPOP myList | |
"msg1" |
不过,通过 RPUSH/LPOP 或者 LPUSH/RPOP 这样的方式存在性能问题,需要不断轮询去调用 RPOP 或 LPOP 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
因此,Redis 还提供了 BLPOP 、 BRPOP 这种阻塞式读取的命令(带 B:Bloking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后,再返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息。
# 超时时间为 10s | |
# 如果有数据则立刻返回,否则最多等待 10 秒 | |
> BRPOP myList 10 | |
null |
List 实现消息队列功能太简单,像 ACK 机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。
# 发布订阅(pub/sub)实现方式
Redis 2.0 引入了发布订阅 (pub/sub) 功能,解决了 List 实现消息队列没有广播机制的问题。

pub/sub 中引入了一个概念叫 channel(频道),发布订阅机制的实现就是基于这个 channel 来做的。
pub/sub 涉及两个角色:
- 发布者(Publisher):通过
PUBLISH投递消息给指定 channel。 - 订阅者(Subscriber,也叫消费者):通过
SUBSCRIBE订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
这里启动 3 个 Redis 客户端来简单演示一下:

pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
# Stream 实现方式
为此,Redis 5.0 新增加的一个数据结构 Stream 来做消息队列。 Stream 支持:
- 发布订阅(pub/sub)模式
- 按照消费者组进行消费(借鉴了 Kafka 消费者组的概念)
- 消息持久化(RDB 和 AOF)
- ACK 机制(通过确认机制来告知已经成功处理了消息)
- 阻塞式获取消息
Stream 的结构如下:

Stream 使用起来相对要麻烦一些,这里就不演示了。而且, Stream 在实际使用中依然会有一些小问题不太好解决,比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
Stream 被用作消息队列时,依赖于下面这些命令:
XADD:向流中添加新的消息。XREAD:从流中读取消息。XREADGROUP:从消费组中读取消息。XRANGE:根据消息 ID 范围读取流中的消息。XREVRANGE:与XRANGE类似,但以相反顺序返回结果。XDEL:从流中删除消息。XTRIM:修剪流的长度,可以指定修建策略。XLEN:获取流的长度。XGROUP:管理消费组,包括创建、删除和修改。XACK:确认消费组中的消息已被处理。XPENDING:查询消费组中挂起(未确认)的消息。XCLAIM:将挂起的消息从一个消费者转移到另一个消费者。XINFO:获取流、消费组或消费者的详细信息。
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方,比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。不过,如果你就是想要用 Redis 来做消息队列的话,那我建议优先考虑 Stream ,这是目前相对最优的 Redis 消息队列实现。
相关阅读:Redis 消息队列发展历程 - 阿里开发者 - 2022。
# Redis 命令
Redis 根据命令所操作对象的不同,可以分为三大类:
- 对 Redis 进行基础性操作的命令
- 对 Key 的操作命令
- 对 Value 的操作命令
# 基础命令
首先通过 redis-cli 命令进入到 Redis 命令行客户端,然后再运行下面的命令:
| 命令 | 介绍 |
|---|---|
PING | 心跳命令,会看到 PONG 响应,则说明该客户端与 Redis 的连接是正常的。 |
SELECT dbindex | 切换数据库。Redis 默认有 16 个数据库,这个在 RDM 图形客户端中可以直观地看到。默认使用的是 0 号 DB,可以通过 select db 索引来切换 DB。 |
DBSIZE | 查看当前数据库中 key 的数量 |
FLUSHDB | 删除当前数据库中的数据 |
FLUSHALL | 删除所有数据库中的数据 |
使用 exit / quit 命令均可退出 Redis 命令行客户端。
# key 相关命令
因此,在介绍 Redis 中常用的 value 数据类型前,先介绍一下 key 相关的命令。
| 命令 | 介绍 |
|---|---|
DEL key | key 存在时,删除 key |
UNLINK key | 非阻塞删除 key,仅仅将 key 从 keyspace 元数据中删除,真正的删除会在后续异步中操作。 |
| DUMP key | 返回 key 被序列化后的值 |
EXISTS key | 检查 key 是否存在 |
EXPIRE key seconds | 以秒为单位,设置 key 的过期时间。默认 -1 表示永不过期。(时间间隔) |
| PEXPIRE key milliseconds | 以毫秒为单位,设置 key 过期时间。(时间间隔) |
EXPIREAT key timestamp | 与 EXPIRE 类似,以秒为单位,不同点在于该命令接受的时间参数是 UNIX 时间戳(unix timestamp)(时刻) |
| PEXPIREAT key milliseconds-timestamp | 以毫秒为单位,设置 key 过期时间的 UNIX 时间戳。(时刻) |
KEYS pattern | 查找所有符合给定模式(pattern)的 key。例如 KEYS * 查看当前数据库的所有 key。 |
MOVE key dbindex[0-15] | 将当前数据库的 key 移动到指定数据库 [0-15] 中,默认为 0 |
SELECT dbindex | 切换到指定的数据库 [0-15],默认为 0 |
DBSIZE | 查看当前数据库的 key 数量 |
FLUSHDB | 清空当前库 |
FLUSHALL | 通杀所有库 |
PERSIST key | 持久保持 key,移除其过期时间 |
TTL key | 以秒为单位,返回 key 的剩余生存时间(TTL,time to live)。其中 -1 表示永不过期,-2 表示已过期。 |
| PTTL key | 以毫秒为单位,返回 key 的剩余生存时间 |
| RANDOMKEY | 从当前数据库中随机返回一个 key |
| RENAME key newkey | 将 key 改名为 newkey |
| RENAMENX key newkey | 仅当 newkey 不存在时,将 key 改名为 newkey |
TYPE key | 返回 key 所存储 value 的数据类型 |
# 🌟Redis 数据类型
前文已声明过 Redis 是基于 Key-Value 的,而 key 类型一般是 String,这里所介绍的数据类型指的是 value 的数据类型。
# 🌟常用数据类型
更多 Redis value 数据类型 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands
Redis 中比较常见的数据类型有下面这些:
- 5 种基础数据类型:
String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。 - 3 种特殊数据类型:
HyperLogLog(基数统计)、Bitmap(位图)、Geospatial(地理位置)。
除了上面提到的之外,还有一些其他的比如 Bloom filter (布隆过滤器)、 Bitfield (位域)。

# 5 种基础数据类型
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串( SDS )、 LinkedList (双向链表)、 Dict (哈希表 / 字典)、 SkipList (跳跃表)、 Intset (整数集合)、 ZipList (压缩列表)、 QuickList (快速列表)。
**5 种基本数据类型对应的底层数据结构** 实现如下表所示:
| String | List | Hash | Set | Zset |
|---|---|---|---|---|
| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
你可以在 Redis 官网上找到 Redis 数据类型 / 结构非常详细的介绍:
- Redis Data Structures
- Redis Data types tutorial
未来随着 Redis 新版本的发布,可能会有新的数据结构出现,通过查阅 Redis 官网对应的介绍,你总能获取到最靠谱的信息。

# String(字符串)
# 介绍
String 是 Redis 中最简单、最常用的一个数据类型。
String 是一种 **二进制安全** 的数据类型,可以用来存储任何类型的数据,比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。

虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(Simple Dynamic String, SDS )。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据,还可以保存二进制数据,并且获取字符串长度复杂度为 O (1)(C 字符串为 O (N))。此外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
# 命令
| 命令 | 介绍 |
|---|---|
| SET key value | 设置指定 key 的值 |
SETNX key value | 只有在 key 不存在时设置 key 的值 |
| GET key | 获取指定 key 的值 |
MSET key1 value1 key2 value2 …… | 设置一个或多个指定 key 的值 |
| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
STRLEN key | 返回 key 所储存的字符串值的长度 |
INCR key | 将 key 中储存的数字值增一 |
DECR key | 将 key 中储存的数字值减一 |
| EXISTS key | 判断指定 key 是否存在 |
DEL key(通用) | 删除指定的 key |
EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
基本操作:
> SET key value | |
OK | |
> GET key | |
"value" | |
> EXISTS key | |
(integer) 1 | |
> STRLEN key | |
(integer) 5 | |
> DEL key | |
(integer) 1 | |
> GET key | |
(nil) |
批量设置:
> MSET key1 value1 key2 value2 | |
OK | |
> MGET key1 key2 # 批量获取多个 key 对应的 value | |
1) "value1" | |
2) "value2" |
计数器(字符串的内容为整数的时候可以使用):
> SET number 1 | |
OK | |
> INCR number # 将 key 中储存的数字值增一 | |
(integer) 2 | |
> GET number | |
"2" | |
> DECR number # 将 key 中储存的数字值减一 | |
(integer) 1 | |
> GET number | |
"1" |
设置过期时间(默认为永不过期):
> EXPIRE key 60 | |
(integer) 1 | |
> SETEX key 60 value # 设置值并设置过期时间 | |
OK | |
> TTL key | |
(integer) 56 |
# String 应用
常规数据的缓存
- 举例:缓存 Session、Token、图片地址、序列化后的对象 (相比较于 Hash 存储更节省内存)。
- 相关命令:
SET、GET。
需要计数的场景
- 举例:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
- 相关命令:
SET、GET、INCR、DECR。
分布式锁
利用 SETNX key value 命令可以实现一个最简易的分布式锁(存在一些缺陷,通常不建议这样实现分布式锁)。
# List(列表)
# 介绍
Redis 中的 List 其实就是链表数据结构的实现。我在 线性数据结构:数组、链表、栈、队列 这篇文章中详细介绍了链表这种数据结构,我这里就不多做介绍了。
许多高级编程语言都内置了链表的实现比如 Java 中的 LinkedList ,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。

# 命令
| 命令 | 介绍 |
|---|---|
RPUSH key value1 value2 ... | 在指定列表的尾部(右边)添加一个或多个元素 |
| LPUSH key value1 value2 ... | 在指定列表的头部(左边)添加一个或多个元素 |
LSET key index value | 将指定列表索引 index 位置的值设置为 value |
RPOP key | 移除并获取指定列表的最后一个元素 (最右边) |
| LPOP key | 移除并获取指定列表的第一个元素 (最左边) |
LLEN key | 获取列表元素数量 |
LRANGE key start end | 获取列表 start 和 end 之间 的元素 |
通过 RPUSH/LPOP 或者 LPUSH/RPOP 实现队列(先进先出):
> RPUSH myList value1 | |
(integer) 1 | |
> RPUSH myList value2 value3 | |
(integer) 3 | |
> LPOP myList | |
"value1" | |
> LRANGE myList 0 1 | |
1) "value2" | |
2) "value3" | |
> LRANGE myList 0 -1 | |
1) "value2" | |
2) "value3" |
通过 RPUSH/RPOP 或者 LPUSH/LPOP 实现栈(先进后出):
> RPUSH myList2 value1 value2 value3 | |
(integer) 3 | |
> RPOP myList2 # 将 list 的最右边的元素取出 | |
"value3" |
我专门画了一个图方便大家理解 RPUSH , LPOP , lpush , RPOP 命令:

通过 LRANGE 查看对应下标范围的列表元素:
> RPUSH myList value1 value2 value3 | |
(integer) 3 | |
> LRANGE myList 0 1 | |
1) "value1" | |
2) "value2" | |
> LRANGE myList 0 -1 | |
1) "value1" | |
2) "value2" | |
3) "value3" |
通过 LRANGE 命令,你可以基于 List 实现分页查询,性能非常高!
通过 LLEN 查看链表长度:
> LLEN myList | |
(integer) 3 |
# 应用
信息流展示
- 举例:最新文章、最新动态。
- 相关命令:
LPUSH、LRANGE。
消息队列
List 可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
相对来说,Redis 5.0 新增加的一个数据结构 Stream 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
# Hash(哈希)
# 介绍
Redis 中的 Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。
Hash 类似于 JDK1.8 前的 HashMap ,内部实现也差不多 (数组 + 链表)。不过,Redis 的 Hash 做了更多优化。

# 命令
| 命令 | 介绍 |
|---|---|
HSET key field value | 将指定哈希表 key 中指定字段 field 的值设置为 value |
| HSETNX key field value | 仅当指定字段 field 不存在时,设置其值 |
HMSET key field1 value1 field2 value2 ... | 同时将一个或多个 field-value (域 - 值) 对设置到指定哈希表 key 中 |
| HGET key field | 获取指定哈希表中指定字段的值 |
| HMGET key field1 field2 ... | 获取指定哈希表中一个或者多个指定字段的值 |
HGETALL key | 获取指定哈希表 key 中所有的 **键值对** |
HEXISTS key field | 查看指定哈希表中指定的字段是否存在 |
HDEL key field1 field2 ... | 删除一个或多个哈希表字段 |
HLEN key | 获取指定哈希表中字段的数量 |
HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
模拟对象数据存储:
> HMSET userInfoKey name "guide" description "dev" age 24 | |
OK | |
> HEXISTS userInfoKey name # 查看 key 对应的 value 中指定的字段是否存在。 | |
(integer) 1 | |
> HGET userInfoKey name # 获取存储在哈希表中指定字段的值。 | |
"guide" | |
> HGET userInfoKey age | |
"24" | |
> HGETALL userInfoKey # 获取在哈希表中指定 key 的所有字段和值 | |
1) "name" | |
2) "guide" | |
3) "description" | |
4) "dev" | |
5) "age" | |
6) "24" | |
> HSET userInfoKey name "GuideGeGe" | |
> HGET userInfoKey name | |
"GuideGeGe" | |
> HINCRBY userInfoKey age 2 | |
(integer) 26 |
# 应用
对象数据存储场景
- 举例:用户信息、商品信息、文章信息、购物车信息。
- 相关命令:
HSET(设置单个字段的值)、HMSET(设置多个字段的值)、HGET(获取单个字段的值)、HMGET(获取多个字段的值)。
# Set(集合)
# 介绍
Redis 中的 Set 类型是一种无序集合,集合中的 **元素没有先后顺序,但都唯一(不重复)**,有点类似于 Java 中的 HashSet 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。

# 命令
| 命令 | 介绍 |
|---|---|
SADD key member1 member2 ... | 向指定集合添加一个或多个元素 |
SMEMBERS key | 获取指定集合中的所有元素 |
SCARD key | 获取指定集合的元素数量 |
SISMEMBER key member | 判断指定元素是否在指定集合中 |
SINTER key1 key2 ... | 获取给定所有集合的交集 |
| SINTERSTORE destination key1 key2 ... | 将给定所有集合的交集存储在 destination 中 |
SUNION key1 key2 ... | 获取给定所有集合的并集 |
| SUNIONSTORE destination key1 key2 ... | 将给定所有集合的并集存储在 destination 中 |
SDIFF key1 key2 ... | 获取给定所有集合的差集 |
| SDIFFSTORE destination key1 key2 ... | 将给定所有集合的差集存储在 destination 中 |
SPOP key count | 随机移除并获取指定集合中一个或多个元素 |
SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
基本操作:
> SADD mySet value1 value2 | |
(integer) 2 | |
> SADD mySet value1 # 不允许有重复元素,因此添加失败 | |
(integer) 0 | |
> SMEMBERS mySet | |
1) "value1" | |
2) "value2" | |
> SCARD mySet | |
(integer) 2 | |
> SISMEMBER mySet value1 | |
(integer) 1 | |
> SADD mySet2 value2 value3 | |
(integer) 2 |
mySet:value1、value2mySet2:value2、value3
求交集:
> SINTERSTORE mySet3 mySet mySet2 | |
(integer) 1 | |
> SMEMBERS mySet3 | |
1) "value2" |
求并集:
> SUNION mySet mySet2 | |
1) "value3" | |
2) "value2" | |
3) "value1" |
求差集:
> SDIFF mySet mySet2 # 差集是由所有属于 mySet 但不属于 A 的元素组成的集合 | |
1) "value1" |
# Set 应用
需要存放的数据不能重复的场景
- 举例:网站 UV (Unique Visitor,独立访客)统计(数据量巨大的场景还是
HyperLogLog更适合一些)、点赞数统计等场景。 - 相关命令:
SCARD(获取集合数量)。

需要获取多个数据源交集、并集和差集的场景
- 举例:共同好友 (交集)、共同粉丝 (交集)、共同关注 (交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集 + 交集) 等场景。
- 相关命令:
SINTER(交集)、SINTERSTORE(交集)、SUNION(并集)、SUNIONSTORE(并集)、SDIFF(差集)、SDIFFSTORE(差集)。

需要随机获取数据源中的元素的场景
- 举例:抽奖系统、随机点名等场景。
- 相关命令:
SPOP(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、SRANDMEMBER(随机获取集合中的元素,适合允许重复中奖的场景)。
# Sorted Set/Zset(有序集合)
# 介绍
Sorted Set 也称 Zset,和 Set 相比 **增加了一个权重参数** score ,使得集合中的元素能够按 score 进行 **有序排列**,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。

# 命令
| 命令 | 介绍 |
|---|---|
ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
ZCARD KEY | 获取指定有序集合的元素数量 |
ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
ZINTERSTORE destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
ZREVRANK key member | 获取指定有序集合中指定元素的排名 (score 从大到小排序) |
基本操作:
> ZADD myZset 2.0 value1 1.0 value2 | |
(integer) 2 | |
> ZCARD myZset | |
2 | |
> ZSCORE myZset value1 | |
2.0 | |
> ZRANGE myZset 0 1 | |
1) "value2" | |
2) "value1" | |
> ZREVRANGE myZset 0 1 | |
1) "value1" | |
2) "value2" | |
> ZADD myZset2 4.0 value2 3.0 value3 | |
(integer) 2 |
myZset:value1(2.0)、value2(1.0) 。myZset2:value2(4.0)、value3(3.0) 。
获取指定元素的排名:
> ZREVRANK myZset value1 | |
0 | |
> ZREVRANK myZset value2 | |
1 |
求交集:
> ZINTERSTORE myZset3 2 myZset myZset2 | |
1 | |
> ZRANGE myZset3 0 1 WITHSCORES | |
value2 | |
5 |
求并集:
> ZUNIONSTORE myZset4 2 myZset myZset2 | |
3 | |
> ZRANGE myZset4 0 2 WITHSCORES | |
value1 | |
2 | |
value3 | |
3 | |
value2 | |
5 |
求差集:
> ZDIFF 2 myZset myZset2 WITHSCORES | |
value1 | |
2 |
# Zset 应用
需要根据某个权重对元素进行排序(排行榜)的场景
- 举例:各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
- 相关命令:
ZRANGE(从小到大排序)、ZREVRANGE(从大到小排序)、ZREVRANK(获取指定元素的排名)。

Sorted Set 能够轻松应对百万级别的用户数据排序,简直就是专门为排行榜设计的数据结构!下面详细介绍一下如何使用 Sorted Set 来设计制作一个排行榜:
| User | Score |
|---|---|
| user1 | 112.0 |
| user2 | 100.0 |
| user3 | 123.0 |
| user4 | 100.0 |
| user5 | 33.0 |
| user6 | 993.0 |
把上表中的数据添加到 Sorted Set 中:
# 通过 zadd 命令添加了 6 个元素到 cus_order_set 中 | |
127.0.0.1:6379> ZADD cus_order_set 112.0 user1 100.0 user2 123.0 user3 100.0 user4 33.0 user5 993.0 user6 | |
(integer) 6 |

查看包含所有用户的排行榜: 通过 ZRANGE (从小到大排序) / ZREVRANGE (从大到小排序)
# -1 代表的是全部的用户数据, | |
127.0.0.1:6379> ZREVRANGE cus_order_set 0 -1 | |
1) "user6" | |
2) "user3" | |
3) "user1" | |
4) "user4" | |
5) "user2" | |
6) "user5" |
查看只包含前 3 名的排行榜: 限定范围区间即可。
# 0 为 start 2 为 stop | |
127.0.0.1:6379> ZREVRANGE cus_order_set 0 2 | |
1) "user6" | |
2) "user3" | |
3) "user1" |
查询某个用户的分数: 通过 ZSCORE 命令即可。
127.0.0.1:6379> ZSCORE cus_order_set "user1" | |
"112" |
查询某个用户的排名: 通过 ZREVRANK 命令即可。
127.0.0.1:6379> ZREVRANK cus_order_set "user3"
(integer) 1 # user3 排名第2
对用户的排名数据进行更新: 通过 ZINCRBY 命令即可。
# 对 user1 的分数加 2 | |
127.0.0.1:6379> ZINCRBY cus_order_set +2 "user1" | |
"114" | |
# 对 user1 的分数减 1 | |
127.0.0.1:6379> ZINCRBY cus_order_set -1 "user1" | |
"113" | |
# 查看 user1 的分数 | |
127.0.0.1:6379> ZSCORE cus_order_set "user1" | |
"113" |
除了我上面提到的之外,还有一些其他的命令来帮助你解决更多排行榜场景的需求,想要深入研究的小伙伴可以仔细学习哦!
不过,需要注意的一点是:Redis 中只保存了排行榜展示所需的数据,需要用户的具体信息数据的话,还是需要去对应的数据库(比如 MySQL)中查。
你以为这样就完事了? 不存在的!还有一些无法仅仅通过 Redis 提供的命令解决的场景。
比如,如何实现多条件排序? 其实,答案也比较简单,对于大部分场景,我们直接对 score 值做文章即可。
更具体点的话就是,我们根据特定的条件来拼接 score 值即可。比如我们还要加上时间先后条件的话,直接在 score 值添加上时间戳即可。
再比如,如何实现指定日期(比如最近 7 天)的用户数据排序?
我说一种比较简单的方法:我们把每一天的数据都按照日期为名字,比如 20350305 就代表 2035 年 3 月 5 号。
如果我们需要查询最近 n 天的排行榜数据的话,直接 ZUNIONSTORE 来求 n 个 sorted set 的并集即可。
ZUNIONSTORE last_n_days n 20350305 20350306.... |
我不知道大家看懂了没有,我这里还是简单地造一些数据模拟一下吧!
# 分别添加了 3 天的数据 | |
127.0.0.1:6379> ZADD 20350305 112.0 user1 100.0 user2 123.0 user3 | |
(integer) 3 | |
127.0.0.1:6379> ZADD 20350306 100.0 user4 | |
(integer) 1 | |
127.0.0.1:6379> ZADD 20350307 33.0 user5 993.0 user6 | |
(integer) 2 |
通过 ZUNIONSTORE 命令来查看最近 3 天的排行榜情况:
127.0.0.1:6379> ZUNIONSTORE last_n_days 3 20350305 20350306 20350307 | |
(integer) 6 |
现在,这 3 天的数据都集中在了 last_n_days 中。
127.0.0.1:6379> ZREVRANGE last_n_days 0 -1 | |
1) "user6" | |
2) "user3" | |
3) "user1" | |
4) "user4" | |
5) "user2" | |
6) "user5" |
如果一个用户同时在多个 sorted set 中的话,它最终的 score 值就等于这些 sorted set 中该用户的 score 值之和。
既然可以求并集,那必然也可以求交集。你可以通过 ZINTERSTORE 命令来求多个 n 个 sorted set 的交集。
有哪些场景可以用到多个 sorted set 的交集呢? 比如每日打卡的场景,你对某一段时间每天打卡的人进行排序。
这个命令还有一个常用的权重参数 weights (默认为 1)。在进行并集 / 交集的过程中,每个集合中的元素会将自己的 score * weights 。
我下面演示一下这个参数的作用。
# staff_set 存放员工的排名信息 | |
127.0.0.1:6379> ZADD staff_set 3.0 staff1 4.0 staff2 | |
(integer) 2 | |
# staff_set 存放管理者的排名信息 | |
127.0.0.1:6379> ZADD manager_set 1.0 manager1 2.0 manager2 | |
(integer) 2 |
如果,我们需要将员工和管理者放在一起比较,不过,两者权重分别为 1 和 3。
# staff_set 的权重为 1 manager_set 的权重为 3 | |
127.0.0.1:6379> ZUNIONSTORE all_user_set 2 staff_set manager_set WEIGHTS 1 3 | |
(integer) 4 |
最终排序的结果如下:
127.0.0.1:6379> ZREVRANGE all_user_set 0 -1 | |
1)"manager2" | |
2)"staff2" | |
3)"staff1" | |
4)"manager1" |
需要存储的数据有优先级的场景 比如优先级任务队列。
- 举例:优先级任务队列。
- 相关命令:
ZRANGE(从小到大排序)、ZREVRANGE(从大到小排序)、ZREVRANK(指定元素排名)。
# 小结
| 数据类型 | 说明 |
|---|---|
| String | 一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
| Hash | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
| Set | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 HashSet 。 |
| Zset | 和 Set 相比,Sorted Set 增加了一个权重参数 score ,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。 |
# 3 种特殊数据类型
# Bitmap(位图)
# 介绍
官网介绍:Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 232 个不同的位。
Bitmap 存储的是 **连续的二进制数字**(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。

# 命令
| 命令 | 介绍 |
|---|---|
SETBIT key offset value | 设置指定 offset 位置的值 |
GETBIT key offset | 获取指定 offset 位置的值 |
BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
Bitmap 基本操作演示:
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位 | |
> SETBIT mykey 7 1 | |
(integer) 0 | |
> SETBIT mykey 7 0 | |
(integer) 1 | |
> GETBIT mykey 7 | |
(integer) 0 | |
> SETBIT mykey 6 1 | |
(integer) 0 | |
> SETBIT mykey 8 1 | |
(integer) 0 | |
# 通过 bitcount 统计被被设置为 1 的位的数量。 | |
> BITCOUNT mykey | |
(integer) 2 |
# Bitmap 应用
需要保存状态信息(0/1 即可表示)的场景
- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
- 相关命令:
SETBIT、GETBIT、BITCOUNT、BITOP。
# HyperLogLog(基数统计)
# 介绍
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting (LLC) 优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近 264 个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
- 稀疏矩阵:计数较少的时候,占用空间很小。
- 稠密矩阵:计数达到某个阈值的时候,占用 12k 的空间。
Redis 官方文档中有对应的详细说明:

基数计数概率算法 **为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差**(标准误差为 0.81% )。

HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原理以及在 Redis 中的实现可以看这篇文章:HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的 。
再推荐一个可以帮助理解 HyperLogLog 原理的工具:Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure 。
除了 HyperLogLog 之外,Redis 还提供了其他的概率数据结构,对应的官方文档地址:https://redis.io/docs/data-types/probabilistic/ 。
# 命令
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
| 命令 | 介绍 |
|---|---|
PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
HyperLogLog 基本操作演示:
> PFADD hll foo bar zap | |
(integer) 1 | |
> PFADD hll zap zap zap | |
(integer) 0 | |
> PFADD hll foo bar | |
(integer) 0 | |
> PFCOUNT hll | |
(integer) 3 | |
> PFADD some-other-hll 1 2 3 | |
(integer) 1 | |
> PFCOUNT hll some-other-hll | |
(integer) 6 | |
> PFMERGE desthll hll some-other-hll | |
"OK" | |
> PFCOUNT desthll | |
(integer) 6 |
# 应用
数据量巨大(百万、千万级别以上)的计数场景
- 举例:热门网站每日 / 每周 / 每月访问 ip 数统计、热门帖子 uv 统计
- 相关命令:
PFADD、PFCOUNT
# Geospatial(地理位置)
# 介绍
Geospatial index(地理空间索引,简称 GEO) 主要 **用于存储地理位置信息,基于 Sorted Set 实现**。
通过 GEO 我们可以轻松实现两个位置距离的计算、获取指定位置附近的元素等功能。

# 命令
| 命令 | 介绍 |
|---|---|
GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC (由近到远)、DESC(由远到近)、Count (数量) 等参数 |
GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
基本操作:
> GEOADD personLocation 116.33 39.89 user1 116.34 39.90 user2 116.35 39.88 user3 | |
3 | |
> GEOPOS personLocation user1 | |
116.3299986720085144 | |
39.89000061669732844 | |
> GEODIST personLocation user1 user2 km | |
1.4018 |
通过 Redis 可视化工具查看 personLocation ,果不其然,底层就是 Sorted Set。
GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换成了一个整数,这个整数作为 Sorted Set 的 score (权重参数) 使用。

获取指定位置范围内的其他元素:
> GEORADIUS personLocation 116.33 39.87 3 km | |
user3 | |
user1 | |
> GEORADIUS personLocation 116.33 39.87 2 km | |
> GEORADIUS personLocation 116.33 39.87 5 km | |
user3 | |
user1 | |
user2 | |
> GEORADIUSBYMEMBER personLocation user1 5 km | |
user3 | |
user1 | |
user2 | |
> GEORADIUSBYMEMBER personLocation user1 2 km | |
user1 | |
user2 |
GEORADIUS 命令的底层原理解析可以看看阿里的这篇文章:Redis 到底是怎么实现 “附近的人” 这个功能的呢? 。
移除元素:
GEO 底层是 Sorted Set ,你可以对 GEO 使用 Sorted Set 相关的命令。
> ZREM personLocation user1 | |
1 | |
> ZRANGE personLocation 0 -1 | |
user3 | |
user2 | |
> ZSCORE personLocation user2 | |
4069879562983946 |
# 应用
需要管理使用地理空间数据的场景
- 举例:附近的人
- 相关命令:
GEOADD、GEORADIUS、GEORADIUSBYMEMBER
# 小结
| 数据类型 | 说明 |
|---|---|
| Bitmap | 可以将 Bitmap 看作一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近 2^64 个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 0.81% )。 |
| Geospatial index | Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。 |
# String 应用场景
[String 应用](#String 应用)
# 对象数据的存储建议使用 String
- String 存储的是序列化后的对象数据,存放的是整个对象。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动,或者需要经常单独查询对象中的个别字段信息,Hash 就非常适合。
- String 存储对象相对更加节省内存,缓存相同数量的对象数据,String 消耗的内存约是 Hash 的一半。并且,String 存储具有多层嵌套的对象时,也方便很多。如果系统对性能和资源消耗非常敏感的话,String 就非常适合。
在绝大部分情况,我们建议使用 String 来存储对象数据即可!
# 🌟String 的底层实现:SDS

# SDS 介绍
Redis 是基于 C 语言编写的,但 Redis 的 String 类型的底层实现并不是 C 语言中的字符串(即以空字符 \0 结尾的字符数组),而是自己编写了 **SDS(Simple Dynamic String,简单动态字符串)** 来作为底层实现。
SDS 最早是 Redis 作者为日常 C 语言开发而设计的 C 字符串,后来被应用到了 Redis 上,并经过了大量的修改完善以适合高性能操作。
# SDS 结构
Redis7.0 的 SDS 的部分源码如下:
/* Note: sdshdr5 is never used, we just access the flags byte directly. | |
* However is here to document the layout of type 5 SDS strings. */ | |
struct __attribute__ ((__packed__)) sdshdr5 { | |
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */ | |
char buf[]; | |
}; | |
struct __attribute__ ((__packed__)) sdshdr8 { | |
uint8_t len; /* used */ | |
uint8_t alloc; /* excluding the header and null terminator */ | |
unsigned char flags; /* 3 lsb of type, 5 unused bits */ | |
char buf[]; | |
}; | |
struct __attribute__ ((__packed__)) sdshdr16 { | |
uint16_t len; /* used */ | |
uint16_t alloc; /* excluding the header and null terminator */ | |
unsigned char flags; /* 3 lsb of type, 5 unused bits */ | |
char buf[]; | |
}; | |
struct __attribute__ ((__packed__)) sdshdr32 { | |
uint32_t len; /* used */ | |
uint32_t alloc; /* excluding the header and null terminator */ | |
unsigned char flags; /* 3 lsb of type, 5 unused bits */ | |
char buf[]; | |
}; | |
struct __attribute__ ((__packed__)) sdshdr64 { | |
uint64_t len; /* used */ | |
uint64_t alloc; /* excluding the header and null terminator */ | |
unsigned char flags; /* 3 lsb of type, 5 unused bits */ | |
char buf[]; | |
}; |
通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型的 SDS,从而减少内存的使用。
| 类型 | 字节 | 位 |
|---|---|---|
| sdshdr5 | < 1 | <8 |
| sdshdr8 | 1 | 8 |
| sdshdr16 | 2 | 16 |
| sdshdr32 | 4 | 32 |
| sdshdr64 | 8 | 64 |

对于后四种实现都包含了下面这 4 个属性:
- 字段
len记录字符串长度,即已使用的字符串空间:实现了 O (1) 复杂度的strlen操作,并保证了二进制安全性; - 字段
alloc记录分配的内存大小,即总共可用的字符串空间:这使得修改字符串的时候可以通过计算,仅当空间不足时再扩展; - 字段
flags表示不同的 SDS 类型:Redis 在内部针对区分了多种 SDS 类型,Redis 会根据初始化的长度决定使用哪种类型的 SDS,有效的节省内存。 - 字段
buf[]实际存储字符串的数组
# SDS 优点
SDS 相比于 C 语言中的字符串有如下提升:
- 可以避免缓冲区溢出:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
- 高效的字符串长度计算:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O (n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O (1)。
- 减少了修改时的内存重新分配次数:为了避免修改(增加 / 减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了追加字符串时的空间预分配和截取字符串时的惰性空间释放两种优化策略,最大程度地减少了修改时的内存重新分配次数。
- 空间预分配:当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
- 惰性空间释放:当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
- 二进制安全:C 语言中的字符串以空字符
\0作为字符串结束的标识,但这可能因特殊字符引发异常,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 不需要根据\0特殊字符来判断字符串是否已经结束,而是使用 len 属性判断即可, 因此 SDS 可以存储任何二进制数据,无需担心因特殊字符引发异常。 - 节省内存:Redis 设计了五种不同类型的 SDS,每种对应某一大小范围的字符串,因此可以根据字符串的大小选择占用空间最少的 SDS 类型,并且不使用编译器的内存对齐,而是按实际大小分配内存,最大程度节省了内存。
# SDS 旧版本结构
🤐 多提一嘴,很多文章里 SDS 的定义是下面这样的:
struct sdshdr { | |
unsigned int len; // 记录 buf 数组中已使用字节的数量 = sds 所保存字符串的长度 | |
unsigned int free; // 记录 buf 数组中未使用字节的数量 | |
char buf[]; // 字节数组,用于保存字符串 | |
}; |


这个也没错,Redis 3.2 之前就是这样定义的。后来,由于这种方式的定义存在问题, len 和 free 的定义用了 4 个字节,造成了浪费。Redis 3.2 之后,Redis 改进了 SDS 的定义,将其划分为了现在的 5 种类型。
# 购物车信息的存储建议使用 Hash
你肯定会问:购物车信息也是对象数据,前文不是说了建议使用 String 存储对象数据吗?
因为购物车中的商品频繁修改和变动,购物车信息建议使用 Hash 存储:
- 用户 id 为 key
- 商品 id 为 field,商品数量为 value

那用户购物车信息的维护具体应该怎么操作呢?
- 用户添加商品就是往 Hash 里面增加新的 field 与 value;
- 查询购物车信息就是遍历对应的 Hash;
- 更改商品数量直接修改对应的 value 值(直接 set 或者做运算皆可);
- 删除商品就是删除 Hash 中对应的 field;
- 清空购物车直接删除对应的 key 即可。
这里只是以业务比较简单的购物车场景举例,实际电商场景下,field 只保存一个商品 id 是没办法满足需求的。
# 使用 Sorted Set 实现排行榜
[Zset 应用](#Zset 应用)
# Set 应用场景
[Set 应用](#Set 应用)
# 使用 Set 实现抽奖系统
如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
SADD key member1 member2 ...:向指定集合添加一个或多个元素。SPOP key count:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。SRANDMEMBER key count:随机获取指定集合中指定数量的元素,适合允许重复中奖的场景。
# 🌟集合的底层实现
Redis 中对于 Set 类型的底层实现,直接采用了 hashTable。
对于 Hash 与 ZSet 集合,其底层的实现实际有两种:
zipList(压缩列表)skipList(跳跃列表)
这两种实现对于用户来说是透明的,但用户写入不同的数据,系统会自动使用不同的实现。只要同时满足配置文件 redis.conf 中相关集合元素数量阈值、元素大小阈值两个条件,使用的就是压缩列表 zipList;只要有一个条件不满足,使用的就是跳跃列表 skipList。
例如,对于 ZSet 集合中这两个条件如下:
- 集合元素个数小于 redis.conf 中 zset-max-ziplist-entries 属性的值,其默认值为 128
- 每个集合元素大小都小于 redis.conf 中 zset-max-ziplist-value 属性的值,其默认值为 64 字节
# zipList(压缩列表)
zipList,通常称为压缩列表,是一个经过特殊编码的用于存储字符串或整数的 **双向链表**。
其底层数据结构由在内存上是连续存放的三部分构成:

- head:10 字节
- zlbytes(列表长度):4 字节,存放 zipList 列表整体数据结构所占的字节数,包括 zlbytes 本身的长度。
- zltail(尾 entry 的偏移量):4 字节,用于存放 zipList 中最后一个 entry 在整个数据结构中的偏移量(字节)。该数据的存在可以快速定位列表的尾 entry 位置,以方便操作。
- zllen(entry 个数):2 字节,用于存放 zipList 包含的 entry 个数。由于其只有 16 位,所以 zipList 最多可以含有的 entry 个数为 216-1 = 65535 个。
- entries:真正的列表,由很多的元素 entry 构成。由于不同的元素类型、数值的不同,从而导致每个 entry 的长度不同。
- prevlength(前一个 entry 的长度): 1/3 字节,用于记录前一个 entry 的长度,以实现逆序遍历。默认长度为 1 字节,只要上一个 entry 的长度小于 254 字节, prevlength 就占 1 字节,否则其会自动扩展为 3 字节长度。
- encoding(data 具体类型):1/2/5 字节,用于标志后面的 data 的具体类型。如果 data 为整数类型, encoding 固定长度为 1 字节。如果 data 为字符串类型,则 encoding 长度可能会是 1 字节、 2 字
节或 5 字节。 data 字符串不同的长度,对应着不同的 encoding 长度。 - data(真正的数据):数据类型只能是整数类型或字符串类型,不同的数据占用的字节长度不同。
- end:只包含一部分
- zlend(zipList 结束标记):1 字节,值固定为 255,即二进制位为全 1,表示一个 zipList 列表的结束。
# listPack(紧凑列表)
重写并替代 zipList(压缩列表)
ziplist 实现复杂,为了逆序遍历,每个 entry 中包含前一个 entry 的长度,这样会导致在 ziplist 中间修改或者插入 entry 时需要进行级联更新,在高并发的写操作场景下会极度降低 Redis 的性能。为了实现更紧凑、更快的解析,更简单的实现,重写实现了 ziplist,并命名为 listPack。
在 Redis 7.0 中,已经将 zipList 全部替换为了 listPack,但为了兼容性,在配置中也保留了 zipList 的相关属性。
与 zipList 一样,listPack 也是一个经过特殊编码的用于存储字符串或整数的 **双向链表**。
其底层数据结构也由在内存上也是连续存放的三部分构成:
listPack 与 zipList 的 **重大区别:head 与 entry 的结构**。表示列表结束的 end 与 zipList 的 zlend 是相同的,占一个字节,且 8 位全为 1

head:6 字节
与 zipList 的 head 相比最大的变化:不再记录尾 entry 的偏移量
- totalBytes(列表长度):4 字节,用于存放 listPack 列表整体数据结构所占的字节数,包括 totalBytes 本身的长度。
- elemNum(entry 个数):2 字节,用于存放列表包含的 entry 个数。其意义与 zipList 中 zllen 的相同。
entries:真正的列表,由很多的元素 entry 构成。由于不同的元素类型、数值的不同,从而导致每个 entry 的长度不同。
与 zipList 的 entries 相比最大的变化:不再记录前一个 entry 长度的 prevlength,而是记录当前 entry 长度的 element-total-len。而这个改变仍然可以实现逆序遍历,但却避免了由于在列表中间修改或插入 entry 时引发的级联更新。
- encoding(data 具体类型):1/2/3/4/5/9 字节,用于标志后面的 data 的具体类型。如果 data 为整数类型,encoding 长度可能会是 1、 2、 3、 4、 5 或 9 字节。不同的字节长度,其标识位不同。如果 data 为字符串类型,则 encoding 长度可能会是 1、 2 或 5 字节。 data 字符串不同的长度,对应着不同的 encoding 长度。
- data(真正的数据):只能是整数类型或字符串类型。不同的数据占用的字节长度不同。
- element-total-len(当前 entry 的长度):1/2/3/4/5 字节,用于记录当前 entry 的长度,以实现逆序遍历。由于其特殊的记录方式,使其本身占有的字节数据可能会是 1、 2、 3、 4 或 5 字节。
end:只包含一部分
- zlend(zipList 结束标记):1 字节,值固定为 255,即二进制位为全 1,表示一个 zipList 列表的结束。
# 🌟skipList(跳跃列表 / 跳表)
skipList,跳跃列表,简称跳表,是一种随机化的数据结构,基于并联的链表,实现简单,查找效率较高。简单来说跳表也是链表的一种,只不过它 **在链表的基础上增加了跳跃功能**。也正是这个跳跃功能,使得在查找元素时,能够提供较高的效率。
# 原理
假设有一个带头、尾结点的有序链表。

在该链表中,如果要查找某个数据,需要从头开始逐个进行比较,直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点,或者找到最后尾结点,后两种都属于没有找到的情况。同样,当我们要插入新数据的时候,也要经历同样的查找过程,从而确定插入位置。
为了提升查找效率,在偶数结点上增加一个指针,让其指向下一个偶数结点,形成一个新的链表(高层链表)。

当然,高层链表包含的节点个数只是原来链表的一半。此时再想查找某个数据时,先沿着高层链表进行查找,当遇到第一个比待查数据大的节点时,立即从前一个节点,再回到原链表中进行查找。
例如,若想插入一个数据 20,则先在(8, 19,31, 42)的链表中查找,找到第一个比 20 大的节点 31,然后再在高层链表中找到 31 节点的前一个节点 19,然后再在原链表中获取到其下一个节点值为 23。比 20 大,则将 20 插入到 19 节点与 23 节点之间。若插入的是 25,比节点 23 大,则插入到 23 节点与 31 节点之间。
该方式明显可以减少比较次数,提高查找效率。如果链表元素较多,为了进一步提升查找效率,可以将原链表构建为三层链表,或再高层级链表。

层级越高,查找效率就会越高。
# 存在问题
这种对链表分层级的方式从原理上看确实提升了查找效率,但在实际操作时就出现了问题:由于固定序号的元素拥有固定层级,所以列表元素出现增加或删除的情况下,会导致列表整体元素层级大调整,但这样势必会大大降低系统性能。
例如,对于划分两级的链表,可以规定奇数结点为高层级链表,偶数结点为低层级链表。对于划分三级的链表,可以按照节点序号与 3 取模结果进行划分。但如果插入了新的节点,或删除的原来的某些节点,那么定会按照原来的层级划分规则进行重新层级划分,那么势必会大大降低系统性能。
# 算法优化
为了避免前面的问题,skipList 采用了 **随机分配层级** 方式。即在确定了总层级后,每添加一个新的元素时会自动为其随机分配一个层级。这种随机性就解决了节点序号与层级间的固定关系问题。

从这个 skiplist 的创建和插入过程可以看出,每一个节点的层级数都是随机分配的。而且新插入一个节点不会影响到其它节点的层级数,只需要修改插入节点前后的指针,这就降低了插入操作的复杂度。
skipList 指的就是除了最下面第 1 层链表之外,它会产生若干层稀疏的链表,这些链表里面的指针跳过了一些节点,并且越高层级的链表跳过的节点越多。在查找数据的时先在高层级链表中进行查找,然后逐层降低,最终可能会降到第 1 层链表来精确地确定数据位置。在这个过程中由于跳过了一些节点,从而加快了查找速度。
# quickList(快速列表 / 快表)
从 Redis 3.2 开始成为是 List 的底层实现,替代了 zipList 和 LinkedList
# 原理
quickList,快速列表, quickList 本身是一个双向无循环链表,它的 **每个节点都是一个 zipList**。
zipList 与 linkedList 都存在有明显不足,而 quickList 则对它们进行了改进:吸取了 zipList 和 linkedList 的优点,避开了它们的不足。
quickList 本质上 **是 zipList 和 linkedList 的混合体**,将 linkedList 按段切分,每一段使用 zipList 来紧凑存储若干真正的数据元素,多个 zipList 之间使用双向指针串接起来。

当然,对于每个 zipList 中最多可存放多大容量的数据元素,在配置文件中通过 list-max-ziplist-size 属性可以指定。
# 检索操作
为了更深入的理解 quickList 的工作原理,通过对检索、插入、删除等操作的实现分析来加深理解。
对于 List 元素的检索,都是以其索引 index 为依据的。quickList 由一个个的 zipList 构成,每个 zipList 的 zllen 中记录的就是当前 zipList 中包含的 entry 的个数,即包含的真正数据元素的个数。根据要检索元素的 index,从 quickList 的头节点开始,逐个对 zipList 的 zllen 做 sum 求和,直到找到第一个求和后 sum 大于 index 的 zipList,那么要检索的这个元素就在这个 zipList 中。
# 插入操作
由于 zipList 是有大小限制的,所以在 quickList 中插入一个元素在逻辑上相对就比较复杂一些。假设要插入的元素的大小为 insertBytes ,而查找到的插入位置所在的 zipList 当前的大小为 zlBytes ,那么具体可分为下面几种情况:
- 情况一:当 insertBytes + zlBytes ≤ list-max-ziplist-size 时, 直接插入到 zipList 中相应位置即可
- 情况二:当 insertBytes + zlBytes > list-max-ziplist-size,且插入的位置位于该 zipList 的首部位置,此时需要查看该 zipList 的前一个 zipList 的大小
prev_zlBytes。- 若 insertBytes + prev_zlBytes<= list-max-ziplist-size 时,直接将元素插入到前一个 zipList 的尾部位置即可
- 若 insertBytes + prev_zlBytes> list-max-ziplist-size 时,直接将元素自己构建为一个新的 zipList,并连入 quickList 中
- 情况三:当 insertBytes + zlBytes > list-max-ziplist-size,且插入的位置位于该 zipList 的尾部位置,此时需要查看该 zipList 的后一个 zipList 的大小
next_zlBytes。- 若 insertBytes + next_zlBytes<= list-max-ziplist-size 时,直接将元素插入到后一个 zipList 的头部位置即可
- 若 insertBytes + next_zlBytes> list-max-ziplist-size 时,直接将元素自己构建为一个新的 zipList,并连入 quickList 中
- 情况四:当 insertBytes + zlBytes > list-max-ziplist-size,且插入的位置位于该 zipList 的中间位置,则将当前 zipList 分割为两个 zipList 连接入 quickList 中,然后将元素插入到分割后的前面 zipList 的尾部位置。
# 删除操作
对于删除操作,只需要注意一点,在相应的 zipList 中删除元素后,如果该 zipList 中没有其它元素了,则将该 zipList 删除,将其前后两个 zipList 相连接。
# 使用 Bitmap 统计活跃用户
[Bitmap 应用](#Bitmap 应用)
如果想要使用 Bitmap 统计活跃用户的话,可以使用日期(精确到天)作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1。
初始化数据:
> SETBIT 20210308 1 1 | |
(integer) 0 | |
> SETBIT 20210308 2 1 | |
(integer) 0 | |
> SETBIT 20210309 1 1 | |
(integer) 0 |
统计 20210308~20210309 总活跃用户数:
> BITOP and desk1 20210308 20210309 | |
(integer) 1 | |
> BITCOUNT desk1 | |
(integer) 1 |
统计 20210308~20210309 在线活跃用户数:
> BITOP or desk2 20210308 20210309 | |
(integer) 1 | |
> BITCOUNT desk2 | |
(integer) 2 |
# 使用 HyperLogLog 统计页面 UV(独立访客)
使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
PFADD key element1 element2 ...:添加一个或多个元素到 HyperLogLog 中。PFCOUNT key1 key2:获取一个或者多个 HyperLogLog 的唯一计数。
1、将访问指定页面的每个用户 ID 添加到 HyperLogLog 中。
PFADD PAGE_1:UV USER1 USER2 ...... USERn |
2、统计指定页面的 UV。
PFCOUNT PAGE_1:UV |
# 🌟Redis 持久化机制
Redis 为什么需要持久化?Redis 是一个内存数据库,所以其运行效率非常高。但也存在一个问题:内存中的数据是不持久的,若主机宕机或 Redis 关机重启,则内存中的数据全部丢失。
为了重用数据(比如重启机器、机器故障之后恢复数据)/数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据),Redis 需要持久化功能。
Redis 会按照设置以快照或操作日志的形式将数据持久化到磁盘,对应两种持久化方式:RDB 与 AOF。但实际上,Redis 支持 3 种持久化方式:
- RDB(
RedisDataBase):快照 - AOF(
AppendOnlyFile):只追加文件 - RDB + AOF:RDB 和 AOF 的混合持久化 (Redis 4.0 新增)
# 持久化基本原理

Redis 持久化也称为 钝化 ,是指将内存中数据库的状态描述信息保存到磁盘中。只不过不同的持久化技术,对数据的状态描述信息是不同的,生成的持久化文件也是不同的。但它们的作用都是相同的:避免数据意外丢失。
通过手动方式,或自动定时方式,或自动条件触发方式,将内存中数据库的状态描述信息写入到指定的持久化文件中。当系统重新启动时,自动加载持久化文件,并根据文件中数 \ 据库状态描述信息将数据恢复到内存中,这个数据恢复过程也称为 激活 。这个钝化与激活的过程就是 Redis 持久化的基本原理。
不过从以上分析可知,对于 Redis 单机状态下,无论是手动方式,还是定时方式或条件触发方式,都存在 数据丢失问题 :在尚未手动 / 自动保存时发生了 Redis 宕机状况,那么从上次保存到宕机期间产生的数据就会丢失。不同的持久化方式,其数据的丢失率也是不同的。

需要注意的是,RDB 是默认持久化方式。但 Redis 允许 RDB 与 AOF 两种持久化技术同时开启,此时系统会使用 AOF 方式做持久化,即 AOF 持久化技术的优先级要更高。同样的道理,两种技术同时开启状态下,系统启动时若两种持久化文件同时存在,则优先加载 AOF 持久化文件。
# RDB 持久化
# RDB 简介
RDB(Redis DataBase)将内存中某一时刻的数据以 **全量快照** 的形式写入磁盘中的 rdb 文件。RDB 持久化默认是开启的。当 Redis 启动时会自动读取 rdb 快照文件,将数据从硬盘载入到内存,以恢复 Redis 关机前的数据库状态。

# RDB 快照的触发方式
# 手动 save 命令
线上严禁使用!
通过在 redis-cli 客户端中手动执行 save 命令,可立即让 Redis 保存一次数据库的快照。但是,save 命令在执行期间会阻塞 redis-server 进程,导致 Redis 不能处理任何读写请求,无法对外提供缓存服务,直至持久化过程完毕。

# 手动 bgsave 命令
默认使用
通过在 redis-cli 客户端中执行 bgsave 命令,可立即让 Redis 保存一次数据库的快照。不同于 save 命令的是,正如该命令的名称一样,background save,后台运行 save。bgsave 命令会使服务器进程 redis-server 通过 fork () 生成一个子进程,由该子进程负责完成保存过程,不会阻塞 redis-server 进程对客户端读写请求的处理。

# 自动条件触发
本质:定时自动执行 bgsave 命令
用户可修改配置文件 redis.conf 中 SNAPSHOTTING 的 save 参数,从而设置自动触发快照的时间间隔。比如 save m n 表示每隔 m 秒检测一次数据集,如果检测出超过 n 次变化时,自动触发 RDB 持久化条件,执行快照。
注意,这里说的是每隔 m 秒检测一次,对变化的计数是累加的,只要在某次检测中发现变化数累加值达到 n 次,就会触发 RDB 持久化。而不是要求 n 次变化都集中发生在某个 m 秒内!
Redis 6.0.16 及之前:
- save 900 1:每隔 900s (15min) 检测一次,如果有超过 1 个 key 发生了变化,就写一份新的 RDB 文件
- save 300 10:每隔 300s (5min) 检测一次,如果有超过 10 个 key 发生了变化,就写一份新的 RDB 文件
- save 60 10000:每隔 60s (1min) 检测一次,如果有超过 10000 个 key 发生了变化,就写一份新的 RDB 文件

Redis 6.0.16 以后至今:
- 每隔 3600s(1hour)检测一次,如果有超过 1 处变化,就写一份新的 RDB 文件
- 每隔 300s(5min)检测一次,如果有超过 100 处变化,就写一份新的 RDB 文件
- 每隔 60s(1min)检测一次,如果有超过 10000 处变化,就写一份新的 RDB 文件

# RDB 持久化过程(工作机制)
Redis 进行 bgsave 持久化时,服务器进程 redis-server 会执行以下操作:
- 服务器进程(父进程)调用 forks 生成一个 bgsave 子进程
- bgsave 子进程调用 dump 将内存数据写入到一个 RDB 临时文件中
- 新 RDB 文件覆盖原来的 RDB 文件
bgsave 子进程以 **异步方式** 完成持久化,该过程不会阻塞 redis-server 进程,Redis 可以继续接收并处理用户的读写请求。

其中,bgsave 子进程的详细工作原理如下:

由于子进程可以继承父进程的所有资源,且父进程不能拒绝子进程的继承权。所以,bgsave 子进程有权读取到 redis-server 进程写入到内存中的用户数据,使得将内存数据持久化到 dump.rdb 成为可能。
bgsave 子进程在持久化时首先会将内存中的全量数据 copy 到磁盘中的一个 RDB 临时文件,copy 结束后,再将该文件 rename 为 dump.rdb,替换掉原来的同名文件。
不过,在进行持久化过程中,如果 redis-server 进程接收到了用户写请求,则系统会将内存中发生数据修改的物理块 copy 出一个副本。等内存中的全量数据 copy 结束后,会再将副本中的数据 copy 到 RDB 临时文件。这个副本的生成是由于 Linux 系统的写时复制技术( Copy-On-Write )实现的。
copy-on-write 是 Linux 系统的一种进程管理技术。
原本在 Unix 系统中,当一个主进程通过 fork () 系统调用创建子进程后,内核进程会复制主进程的整个内存空间中的数据,并将其分配给子进程。这种方式存在的问题有以下几点:
- 这个过程非常耗时
- 这个过程降低了系统性能
- 如果主进程修改了其内存数据,子进程副本中的数据是没有修改的。即出现了数据冗余,而冗余数据最大的问题是数据一致性无法保证。
现代的 Linux 则采用了更为有效的方式:写时复制。子进程会继承父进程的所有资源,其中就包括主进程的内存空间。即子进程与父进程共享内存。只要内存被共享,那么该内存就是只读的(写保护的)。而 **写时复制则是在任何一方需要写入数据到共享内存时,都会出现异常,此时内核进程就会将需要写入的数据 copy 出一个副本,写入到另外一块非共享内存区域**。
# RDB 配置项
RDB 相关的配置在配置文件
redis.conf中的 SNAPSHOTTING 部分
| 配置参数 | 介绍 | 示例 |
|---|---|---|
save <seconds> <changes> | 设置快照自动触发的条件(时间间隔、变化数)。默认情况下持久化条件为 save 3600 1 300 100 60 10000 | save m n 表示每隔 m 秒检测一次数据集,如果检测出超过 n 次变化(累积)时,自动触发 RDB 持久化条件,执行快照。 |
dbfilename | 设置 rdb 文件的名称,默认为 dump.rdb | dbfilename dump.rdb |
dir | 设置 rdb 文件的保存路径,默认为 Redis 安装根目录 | dir ./ |
stop-write-on-bgsave-error | 当子进程执行快照保存出现错误时,是否让主进程停止接收新的写请求,默认为 yes | stop-write-on-bgsave-error yes |
rdbcompression | 对于存储到磁盘中的快照,是否采用 LZF 算法对字符串对象进行压缩,默认为 yes。可大幅降低文件的大小,方便保存到磁盘,加速主从集群中从节点的数据同步。 | rdbcompression yes |
rdbchecksum | 是否采用 CRC64 算法对快照文件进行数据校验,默认为 yes | rdbchecksum yes |
sanitize-dump-payload | 设置在加载 RDB 文件或进行持久化时是否开启对 zipList、 listPack 等数据的全面安全检测,该检测可以降低命令处理时发生系统崩溃的可能,默认为 no | sanitize-dump-payload clients 表示只有当客户端连接时检测,排除了加载 RDB 文件与进行持久化时的检测。 |
rdb-del-sync-files | 主从复制时,是否删除用于同步的从机上的 RDB 文件。默认是 no,不删除。不过需要注意,只有当从机的 RDB 和 AOF 持久化功能都未开启时才生效。 | rdb-del-sync-files no |
# RDB 文件结构

RDB 持久化文件 dump.rdb 由五部分构成:
SOF(文件开始标识):是一个长度为 5 的字符串常量 "REDIS",标识 RDB 文件的开始,以便在加载 RDB 文件时可以迅速判断出文件是否是 RDB 文件。
rdb_version(文件版本号):是一个长度为 4 字节的整数
EOF(文件结束标识):长度为 1 字节的常量,用于标识 RDB 数据的结束,校验和的开始。
check_sum(校验和):用于判断 RDB 文件中是否出现数据异常,采用的是 CRC 校验算法。
CRC 校验算法:
在持久化时,先将 SOF、rdb_version 及内存数据库中的数据快照这三者的二进制数据拼接起来,形成一个二进制数(假设称为数 a),然后再使用这个 a 除以校验和 check_sum,此时可获取到一个余数 b,然后再将这个 b 拼接到 a 的后面,形成 databases。
在加载时,需要先使用 check_sum 对 RDB 文件进行数据损坏验证。验证过程:只需将 RDB 文件中除 EOF 与 check_sum 外的数据除以 check_sum。只要除得的余数不是 0,就说明文件发生损坏。当然,如果余数是 0,也不能肯定文件没有损坏。
这种验证算法,是数据损坏校验,而不是数据没有损坏的校验。
databases(数据库):可以包含任意多个非空数据库 database,每个 database 又由三部分构成:
SODB(数据库开始标识)
db_number(数据库编号)
key_value_pairs(键值对数据):每个键值对又由多个描述数据构成:
![image-20231207211310010]()
- VALUE_TYPE
- EXPIRETIME_UNIT(过期时间的单位)
- time(当前键值对的过期时间)

# RDB 优缺点
RDB 持久化的优点:
- 适合大规模的数据恢复
- 按照业务,定时备份
- 对数据完整性和一致性要求不高
- dump.rdb 文件在内存中的加载速度要比 AOF 快得多
RDB 持久化的缺点:
- 一定间隔时间做一次备份,所以如果 Redis 意外 down 掉的话,就会丢失从当前至最近一次快照期间的数据,快照之间的数据会丢失
- 内存数据的全量同步,如果数据量太大会导致 I/O 严重影响服务器性能
- RDB 依赖于主进程的 fork,在更大的数据集中,这可能会导致服务请求的瞬间延迟
- fork 的时候内存中的数据被克降了一份,大致 2 倍的数据膨胀性,需要考虑
# 如何禁用 RDB
将配置文件中的 save 参数设置为空串 "",有两种方式:
命令:
res-cli config set save ""修改配置文件:
![image-20230806152126685]()

# 如何恢复 RDB 文件
当 dump.rdb 文件破损时可以使用 redis-check-rdb 命令进行修复。

# RDB 小结

# AOF 持久化
# AOF 简介
动机:对于 RDB 持久化的快照,如果 Redis 因为某些原因而造成故障停机,那么服务器将丢失最近写入、但仍未保存到快照中的那些数据。因此,Redis 增加了一种 **完全耐久、实时性更好** 的持久化方式:AOF 持久化。
AOF( A ppend O nly F ile)以日志文件( appendonly.aof 文件)的形式来追加记录 Redis 执行过的每个写操作指令。Redis 重启时就根据日志文件的内容将写指令从前到后重新执行一次,以完成数据的恢复工作。
Redis 6.0 之前默认关闭 AOF,Redis 6.0 之后默认开启 AOF。开启 AOF 功能需要在配置文件 redis.conf 中设置配置: appendonly yes 。
# AOF 文件格式
从 Redis 7 开始,采用 Multi Part AOF 机制,将原来的单个 AOF 文件拆分成三类多个 AOF 文件:
- 基本文件(base.rdb/aof):可以是 RDB / AOF 格式,默认为 RDB 格式,即混合式持久化。一般由子线程通过 rewrite 产生,该文件最多只有一个。
- 增量文件(incr.aof):以操作日志形式记录写命令,一般在 rewrite 开始执行时创建,该文件可以有多个。
- 历史文件:由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。
此外,还有清单文件(manifest):该文件首先会按照 seq 序号列举出所有基本文件,基本文件 type 类型为 b,然后再按照 seq 序号再列举出所有增量文件,增量文件 type 类型为 i。对于 Redis 启动时的数据恢复,也会按照该文件由上到下依次加载它们中的数据。可以维护 AOF 文件的创建顺序,保障激活时的应用顺序。
其中基本文件一般为 rdb 格式,在前面已经研究过了。下面就来看一下增量文件与清单文件的内容格式。

# AOF 配置项
| 配置参数 | 介绍 | 示例 |
|---|---|---|
appendonly | 是否开启 AOF | appendonly yes |
appendfilename | 设置 AOF 文件的名称 | appendfilename "appendonly.aof" |
aof-use-rdb-preamble | 设置基本文件为 RDF 格式 / AOF 格式,默认为 yes(RDB 格式),即混合式持久化 | aof-use-rdb-preamble yes |
appenddirname | 设置 AOF 文件目录,默认为 Redis 安装目录 | appenddirname "appendonlydir" |
appendfsync | 设置同步方式(刷盘时机) | appendfsync always/everysec/no |
no-appendfsync-on-rewrite | AOF rewrite 期间是否同步(刷盘) | |
auto-aof-rewrite-percentageauto-aof-rewrite-min-size | rewrite 触发配置、文件重写策略 | auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb |
# AOF 持久化过程(工作基本流程)
AOF 持久化功能的实现可以简单分为 5 步:

命令追加(append):所有的写命令会
append到内存中的 AOF 缓冲区。文件写入(write):将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用
write函数(系统调用)将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。文件同步(fsync):AOF 缓冲区根据对应的持久化方式(
fsync策略)向硬盘做同步操作。这一步需要调用fsync函数(系统调用),fsync针对单个文件操作,对其进行强制硬盘同步,fsync将阻塞直到写入磁盘完成后返回,保证了数据持久化。文件重写(rewrite):随着磁盘上的 AOF 文件越来越大,到达 rewrite 条件时,主线程会 fork 一个子线程 bgrewriteaof 定期 AOF 文件进行重写(根据规则去合并写命令),达到压缩的目的。
如果在 rewrite 过程中又有写操作命令追加,那么这些数据会暂时写入 aof_rewrite_buf 缓冲区。等将全部 rewrite 计算结果写入临时文件后,会先将 aof_rewrite_buf 缓冲区中的数据写入临时文件,然后再 rename 为磁盘文件的原名称,覆盖原文件。
重启加载(load):当 Redis 重启时,可以加载磁盘上的 AOF 文件,执行其中的写命令,进行数据恢复。
Linux 系统直接提供了一些函数用于对文件和设备进行访问和控制,这些函数被称为系统调用(syscall)。
这里对上面提到的一些 Linux 系统调用再做一遍解释:
write:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。fsync:用于强制刷新系统内核缓冲区(同步到到磁盘),会一直阻塞直到确保写磁盘操作结束才会返回。

# AOF 缓冲区的三种写回 / 刷盘策略( fsync 策略)
主要区别在于 fsync 同步 AOF 文件的时机(刷盘)
AOF 缓冲区需要将它保存的写命令写入磁盘上的 AOF 文件,可以修改配置文件中的 参数 appendfsync ,有三种策略:
always:同步写回,主线程调用 write 后,后台线程会立即调用 fsync 函数同步 AOF 文件(刷盘)。fsync 完成后线程返回,这会严重降低 Redis 的性能(write + fsync)everysec:每秒写回,主线程调用 write 后立即返回,由后台线程每秒调用 fsync 函数同步一次 AOF 文件(write + fsync,其中 fsync 间隔为 1 秒)no:操作系统控制的写回,主线程调用 write 后立即返回,让操作系统决定何时进行同步(刷盘)。Linux 中一般为 30 秒一次(write 但不 fsync,其中 fsync 的时机由操作系统决定)

# 🌟AOF 重写机制(Rewrite)
# 何为 rewrite
当 AOF 变得太大时,Redis 能够在后台产生一个新的 AOF 文件,该文件与原有的 AOF 文件所保存的数据库状态一样,但体积更小。
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
AOF 重写机制:启动 AOF 文件的内容压缩,合并其中的命令,只保留可以恢复数据的最小指令集。
重写完成后:
- 重写结果被保存到一个新的 BASE AOF 文件中,文件名上的标号加 1。
- 同时,新建一个空的 INCR AOF 文件,文件名上的标号加 1,旧的被删除。
# rewrite 触发方式
AOF 重写机制有两种触发方式:
自动触发:当 INCR AOF 文件同时满足以下两个条件时,Redis 就会自动启动重写机制,只保留可以恢复数据的最小指令集
INCR AOF 文件负责记录从 AOF 缓冲区写回的写命令
- 当 INCR AOF 文件的大小超过上一次重写结果(即 BASE AOF 文件)大小 1 倍(可以通过配置
auto-aof-rewrite-percentage修改) - 当 INCR AOF 文件的大小超过 64MB(可以通过配置
auto-aof-rewrite-min-size修改)
- 当 INCR AOF 文件的大小超过上一次重写结果(即 BASE AOF 文件)大小 1 倍(可以通过配置
手动触发:可以手动使用命令
bgrewriteaof来重写。
具体过程见脑图,这里只演示 AOF 重写后的效果:


结论:
- AOF 文件重写并不是对原文件进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件。
- AOF 文件重写触发机制:通过 redis.conf 配置文件中的
auto-aof-rewrite-percentage: 默认值为 100,以及auto-aof-rewrite·min-size: 64mb 配置,也就是说默认 Redis 会记录上次重写时的 AOF 大小,默认配置是当 AOF 文件大小是上次 rewrite 后大小的一倍且文件大于 64M 时触发。
# rewrite 原理

在重写开始前,Redis 会创建一个重写子进程
bgrewriteaof,这个子进程会读取现有的 AOF 文件,并将其包含的指令进行分析、压缩,写入到一个临时文件中。与此同时,主进程会将新接收到的写指令一边累积到内存缓冲区中,一边继续写入到原有的 AOF 文件中,这样做是保证原有的 AOF 文件的可用性,避免在重写过程中出现意外。
当重写子进程完成重写工作后,它会给父进程发一个信号,父进程收到信号后就会将内存中缓存的写指令追加到新 AOF 文件中
当追加结束后,Redis 就会用新 AOF 文件来代替旧 AOF 文件,之后再有新的写指令,就都会追加到新的 AOF 文件中
重写 AOF 文件的操作,并没有读取旧的 AOF 文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的 AOF 文件,这点和快照有点类似
# AOF 校验机制
AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
# AOF 记录日志过程
关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复),而 Redis AOF 持久化机制是在执行完命令之后再记录日志。

为什么是在执行完命令之后记录日志呢?
- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
- 在命令执行完之后再记录,不会阻塞当前的命令执行。
这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
- 可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)。
# AOF 优缺点
AOF 有以下优点:
更好地保护数据不丢失
使用 AOF Redis 更加持久∶您可以有不同的 fsync 策略:根本不 fsync、每秒 fsync、每次查询时 fsync。使用每秒 fsync 的默认策略,写入性能仍然很棒。fsync 是使用后台线程执行的,当没有 fsync 正在进行时,主线程将努力执行写入,因此您只能丢失一秒钟的写入。
易修复
AOF 日志是一个仅附加日志,因此不会出现寻道问题,也不会在断电时出现损坏问题。即使由于某种原因(磁盘已满或其他原因)日志以写一半的命令结尾,
redis-check-aof工具也能够轻松修复它。得益于 AOF 的重写机制,能够自我压缩
当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。重写是完全安全的,因为当 Redis 继续附加到旧文件时,会使用创建当前数据集所需的最少操作集生成一个全新的文件,一旦第二个文件准备就绪,Redis 就会切换两者并开始附加到新的那一个。
性能高
文件内容易理解
AOF 以易于理解和解析的格式依次包含所有操作的日志。您甚至可以轻松导出 AOF 文件。
可做紧急恢复
即使您不小心使用该
FLUSHALL命令刷新了所有内容,只要在此期间没有执行日志重写,您仍然可以通过停止服务器、删除最新命令并重新启动 Redis 来保存您的数据集。
AOF 有以下缺点:
- 对于相同的数据集而言,aof 文件要 **远大于 rdb 文件,恢复速度慢于 rdb**
- aof**运行效率要慢于 rdb**,每秒同步策略效率较好,不同步效率和 rdb 相同
# AOF 小结

# RDB-AOF 混合持久化
Redis**默认仅使用 RDB 持久化,禁用 AOF 持久化。但是,当我们手动启用 AOF 持久化后,AOF 的优先级高于 RDB**!对应的数据恢复顺序和加载流程如下图:
# 🌟RDB 与 AOF 对比(持久化技术选型)
RDB:定时一锅端
二者各自的特点如下:
- RDB 持久化(定时一锅端):能够在指定的时间间隔对数据库进行全量快照存储
- AOF 持久化(实时记录写命令):记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,命令以 Redis 协议追加保存每次写的操作到文件末尾。
RDB 优点:
- RDB 文件较小
- 数据恢复速度快
RDB 不足:
- 数据安全性较差
- 写时复制会降低性能
- RDB 文件的可读性较差
AOF 优点:
- 数据安全性高(仅追加新执行的写命令)
- AOF 文件的可读性强,以一种易于理解和解析的格式包含所有写操作的日志
AOF 不足:
- AOF 文件较大
- 数据恢复速度慢
- 写操作会影响性能
RDB + AOF 同时开启时的情况:
- 当 redis 重启的时候会优先载入 AOF 文件来恢复原始的数据,因为在通常情况下 AOF 文件保存的数据集要比 RDB 文件保存的数据集更完整
- RDB 的数据不实时,同时使用两者时服务器重启也只会找 AOF 文件。但是作者建议不要只使用 AOF,因为 RDB 更适合用于备份数据库 (AOF 在不断变化不好备份),留着 rdb 以防万一
综上,
官方推荐 RDB+AOF 混合方式,既能快速加载又能避免丢失过多的数据。配置方式:
对应配置文件中的
aof-use-rdb-preamble,默认为 yes开启 AOF 持久化,对应配置文件中的
appendonly设置为 yes,默认为 no
若对数据安全性要求不高,则推荐使用纯 RDB 持久化方式
不推荐使用纯 AOF 持久化方式,因为 RDB 更适合备份数据库
若 Redis 仅用于缓存,则无需使用任何持久化技术
采用 RDB+AOF 混合持久化时,RDB 做全量持久化,AOF 做增量持久化:
- 先使用 RDB 进行快照存储
- 然后使用 AOF 持久化记录所有的写操作
- 当重写策略满足或手动触发重写的时候,将最新的数据存储为新的 RDB 记录。
- 这样的话,重启服务的时候会从 RDB 和 AOF 两部分恢复数据,既保证了数据完整性,又提高了恢复数据的性能。
简单来说:混合持久化方式产生的文件一部分是 RDB 格式,一部分是 AOF 格式。----》AOF 包括了 RDB 头部 + AOF 混写

# 纯缓存模式
Redis 作为基于 key-value 的内存数据库,Redis 最主要的功能是用作缓存,而 Redis 持久化会消耗 Redis 的性能,因此可以同时关闭 RDB+AOF。
禁用 RDB:
此时仍然可以手动使用命令
SAVE和BGSAVE生成 rdb 文件
命令:
res-cli config set save ""修改配置文件:
![image-20230807012414863]()

禁用 AOF:
此时仍然可以手动使用命令
BGREWRITEAOF生成 aof 文件
- 命令:
res-cli config set appendonly no - 修改配置文件:将
redis.conf中 APPEND ONLY MODE 模块下的参数appendonly设置为 no
# 🌟Redis 宕机后数据会丢失吗?
先说结论:如果没开启任何持久化机制,那么会丢失全部数据,否则只会丢失部分数据,具体丢失多少取决于持久化配置。
Redis 提供了两套持久化机制:
- RDB 快照:定期 fork 一个子进程,生成当前数据库的全量快照,将内存中的数据保存到磁盘中的二进制文件;
- AOF 追加日志:当每个写命令被执行完毕后,它们会被追加写入 AOF 日志文件的末尾。当 Redis 宕机以后,就可以通过 AOF 日志重放这些命令来恢复数据。
对于 RDB 快照,丢失数据的多少取决于宕机时机与快照生成时机:
- 如果宕机发生在 RDB 快照生成后,那么会丢失快照生成期间全部增量数据
- 如果宕机发生在 RDB 快照生成前,那么就会丢掉全部数据
在现实中出于性能考虑,不可能非常频繁地保存快照,因此要防止数据丢失,最终还是主要依靠 AOF 实现。
对于 AOF 追加日志,丢失数据的多少取决于我们设置的刷盘策略:
Always:每条指令执行后都刷盘,最多丢失一条指令Eversec:每秒刷一次盘,最多丢失一秒内的数据No:非主动刷盘,可能丢失上次刷盘后到现在的全部数据
当 Redis 宕机后,就可以通过 AOF 日志重放这些写命令来恢复数据。
# Redis 线程(IO)模型
Redis 客户端提交的各种请求是如何最终被 Redis 处理的?Redis 处理客户端请求所采用的处理架构,称为 Redis 的 IO 模型。不同版本的 Redis 采用的 IO 模型是不同的。
对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作,Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
# 单线程模型
Redis 3.0 及其以前版本


Redis 的单线程模型:所有客户端的请求全部由一个线程处理,采用了 IO 多路复用(multiplexing)技术。
Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为 **文件事件处理器(file event handler)**。
- 文件事件处理器使用 I/O 多路复用程序来同时监听多个套接字(socket),并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
文件事件处理器(file event handler)主要是包含 4 个部分:
- 多个 socket(客户端连接)
- IO 多路复用程序(支持多个客户端连接的关键)
- 文件事件分派器(将 socket 关联到相应的事件处理器)
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)

虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
IO 多路复用技术是一种处理多个 IO 流的技术。它允许单个进程同时监视多个文件描述符(file descriptor,fd),当一个或多个 fd 准备好读或写时,它就可以立即响应。这种技术可以提高系统的并发性和响应能力,减少系统资源的浪费。
在 Linux 中,epoll、select、poll 都是 IO 多路复用的实现方式,都可以监视多个 fd,一旦某个 fd 就绪 (一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。
对于 IO 多路复用的实现方式常见的有三种:
- select 模型:最早的 IO 多路复用机制,同时监视 fd 的数量不超过 1024 个,而且每次只能监视一部分 fd 的状态变化。
- poll 模型:与 select 类似,采用的是轮询算法,但是可以同时监视 fd 的数量更多(65536 个),该模型对客户端的就绪处理是有延迟的。
- epoll 模型:是 Linux 所特有的,采用的是回调方式,支持更多的 fd 数量(8192 个),根据就绪事件发生后的处理方式的不同,又可分为 LT 模型与 ET 模型。
每个客户端若要向 Redis 提交请求,都需要与 Redis 建立一个 socket 连接,并向事件分发器注册一个事件。一旦该事件发生就表明该连接已经就绪。而一旦连接就绪,事件分发器就会感知到,然后获取客户端通过该连接发送的请求,并将由该事件分发器所绑定的这个唯一的线程来处理。如果该线程还在处理多个任务,则将该任务写入到任务队列等待线程处理。
之所以称为事件分发器,是因为它会根据不同的就绪事件,将任务交由不同的事件处理器去处理。
# 混合线程模型
Redis 4.0 开始
从 Redis 4.0 版本开始,Redis 中就开始加入了多线程元素。处理客户端请求的仍是单线程模型,但对于一些比较耗时但又不影响对客户端的响应的操作,就由后台其它线程来处理。例如,持久化、对 AOF 的 rewrite、对失效连接的清理等。
# 多线程模型
Redis 6.0 开始
Redis 6.0 版本,才是真正意义上的多线程模型。因为其 **对于客户端请求的处理采用的是多线程模型**。

多线程 IO 模型中的“多线程” 仅用于接受、解析客户端的请求,然后将解析出的请求写入到任务队列。而 **对具体任务(命令)的处理,仍是由主线程处理**。这样做使得用户无需考虑线程安全问题,无需考虑事务控制,无需考虑像 LPUSH/LPOP 等命令的执行顺序问题。
# 优缺点总结
单线程模型:
- 优点:
- 可维护性高
- 不存在并发读写情况,所以也就不存在执行顺序的不确定性,不存在线程切换开销,不存在死锁问题,不存在为了数据安全而进行的加锁 / 解锁
开销
- 缺点:
- 性能低
- 会形成处理器浪费(单线程只能使用一个处理器)
多线程模型:
- 优点:
- 结合了多线程与单线程的优点,避开了它们的所有不足
- 缺点:
- 非是一个真正意义上的 “多线程”,因为真正处理 “任务” 的线程仍是单线程。所以,其对性能也是有些影响的。
# Redis 6.0 之前为什么不使用多线程?
虽然说 Redis 是单线程模型,但是实际上,Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来 “异步处理”。
为此,Redis 4.0 之后新增了 UNLINK (可以看作是 DEL 的异步版本)、 FLUSHALL ASYNC (清空所有数据库的所有 key,不仅仅是当前 SELECT 的数据库)、 FLUSHDB ASYNC (清空当前 SELECT 数据库中的所有 key)等异步命令。

大体上来说,Redis 6.0 之前主要还是单线程处理。
那 Redis6.0 之前为什么不使用多线程? 我觉得主要原因有 3 点:
- 单线程编程容易并且更容易维护;
- Redis 的性能瓶颈不在 CPU ,主要在内存和网络;
- 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
相关阅读:为什么 Redis 选择单线程模型?
# Redis6.0 之后为何引入了多线程?
Redis6.0 引入多线程主要是为了提高网络 IO 读写性能,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了,执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要设置 IO 线程数 > 1,需要修改 redis 配置文件 redis.conf :
io-threads 4 #设置 1 的话只会开启主线程,官网建议 4 核的机器建议设置为 2 或 3 个线程,8 核的建议设置为 6 个线程 |
另外:
- io-threads 的个数一旦设置,不能通过 config 动态设置。
- 当设置 ssl 后,io-threads 将不工作。
开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 redis.conf :
io-threads-do-reads yes |
但是 **官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启**。
相关阅读:
- Redis 6.0 新特性 - 多线程连环 13 问!
- Redis 多线程网络模型全面揭秘(推荐)
# Redis 后台线程了解吗?
我们虽然经常说 Redis 是单线程模型(主要逻辑是单线程完成的),但实际还有一些后台线程用于执行一些比较耗时的操作:
bio_close_file后台线程:释放 AOF / RDB 等过程中产生的临时文件资源。bio_aof_fsync后台线程:调用fsync函数将系统内核缓冲区还未同步到到磁盘的数据强制刷到磁盘( AOF 文件)。bio_lazy_free后台线程:释放大对象(已删除)占用的内存空间。
在 bio.h 文件中有定义(Redis 6.0 版本,源码地址:https://github.com/redis/redis/blob/6.0/src/bio.h):
#ifndef __BIO_H | |
#define __BIO_H | |
/* Exported API */ | |
void bioInit(void); | |
void bioCreateBackgroundJob(int type, void *arg1, void *arg2, void *arg3); | |
unsigned long long bioPendingJobsOfType(int type); | |
unsigned long long bioWaitStepOfType(int type); | |
time_t bioOlderJobOfType(int type); | |
void bioKillThreads(void); | |
/* Background job opcodes */ | |
#define BIO_CLOSE_FILE 0 /* Deferred close(2) syscall. */ | |
#define BIO_AOF_FSYNC 1 /* Deferred AOF fsync. */ | |
#define BIO_LAZY_FREE 2 /* Deferred objects freeing. */ | |
#define BIO_NUM_OPS 3 | |
#endif |
关于 Redis 后台线程的详细介绍可以查看 Redis 6.0 后台线程有哪些? 这篇就文章。
# Redis 内存管理(缓存数据管理)
# Redis 给缓存数据设置过期时间的意义
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
Redis 自带了给缓存数据设置过期时间的功能,比如:
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期 | |
(integer) 1 | |
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex] pire) | |
OK | |
127.0.0.1:6379> ttl key # 查看数据还有多久过期 | |
(integer) 56 |
注意:Redis 中除了字符串类型有自己独有设置过期时间的命令
setex外,其他方法都需要依靠expire命令来设置过期时间。另外,persist命令可以移除一个键的过期时间。
过期时间除了有助于缓解内存的消耗,还有什么其他用么?
很多时候,我们的 **业务场景就是需要某个数据只在某一时间段内存在**,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
# 过期数据的判断
Redis 通过一个叫做 **过期字典**(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key (键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。

过期字典是存储在 redisDb 这个结构里的:
typedef struct redisDb { | |
... | |
dict *dict; // 数据库键空间,保存着数据库中所有键值对 | |
dict *expires // 过期字典,保存着键的过期时间 | |
... | |
} redisDb; |
# 到期删除策略
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
- 惰性删除:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 定期删除 + 惰性删除 。
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
怎么解决这个问题呢?答案就是:Redis 内存淘汰机制。
# 🌟Redis 内存淘汰机制
相关问题:
- MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
- Redis 缓存满了会触发什么行为?
与到期删除策略不同,内存淘汰策略主要是为了防止运行时内存超过最大内存,所以尽管最终目的都是清理内存中的一些 key,但是它们的应用场景和触发时机是不同的。
从 淘汰范围 来说可以分为三类:
- 不淘汰任何数据
- 只从设置了到期时间的 key 中淘汰
- 从所有 key 中淘汰
从 淘汰算法 来说又可以主要分为三种:
- Random (随机)
- LRU (least recently used,最近最少使用):可以简单理解为 Redis 会在每次访问 Key 的时候记录访问时间,当淘汰时 **优先淘汰最后一次访问距离现在最早的 key**。
- LFU (least frequently used,最少使用):可以理解为 Redis 会在访问 Key 时,根据两次访问时间的间隔计算并累加访问频率指标,当淘汰时优先淘汰访问频率指标最低的 key。相比 LRU 算法,它避免了低频率的大批量查询造成的缓存污染问题。

Redis 提供 8 种数据淘汰策略:
- noeviction:不淘汰任何 key。当内存不足以容纳新写入数据时,新写入操作会报错。这是默认策略,但应该没人使用吧!
- volatile-random:从已设置过期时间的 key(
server.db[i].expires)中随机淘汰一个 key。 - volatile-lru(least recently used):从已设置过期时间的 key 中淘汰最近最少使用的 key。
- volatile-lfu(least frequently used):从已设置过期时间的 key 中淘汰最少使用的 key。
- volatile-ttl(time to live):从已设置过期时间的 key 中淘汰最早过期的 key。
- allkeys-random:从所有 key(
server.db[i].dict)中随机淘汰一个 key。 - allkeys-lru:从所有 key 中淘汰最近最少使用的 key(这个是最常用的)。
- allkeys-lfu:从所有 key 中淘汰最少使用的 key。
# Redis 事务
# 简介
Redis 的事务的本质是 **一组命令的批处理**。这组命令在执行过程中会被按顺序、一次性、串行化全部执行完毕,只要没有出现语法错误,这组命令在执行期间是不会被中断(其他命令无法插入)。
# 常用命令
| 命令 | 描述 | 返回值 |
|---|---|---|
MULTI | 标记一个事务块的开始。随后的一系列指令将在执行 EXEC 时作为一个原子执行。 | OK |
WATCH key [key ...] | 监视若干个 key,如果在事务执行前这些 key 发生改动,那么事务将被打断。在事务中有条件的执行(乐观锁)。 | OK |
EXEC | 执行事务块中所有在排队等待的指令,并将链接状态恢复到正常。 当使用 WATCH 时,只有当被监视的键没有被修改,且允许检查设定机制时, EXEC 会被执行。 | 每个元素与原子事务中的指令一一对应。 使用 WATCH 时,如果被终止, EXEC 则返回一个空的应答集合。 |
UNWATCH | 释放所有被 WATCH 命令监视的 key如果执行 EXEC 或者 DISCARD ,则不需要手动执行该命令。 | OK |
DISCARD | 取消事务,放弃执行事务块中的所有指令。 同时,释放所有被 WATCH 命令监视的 key。 | OK |
Redis 可以通过 MULTI , EXEC , DISCARD 和 WATCH 等命令来实现事务 (Transaction) 功能。
> MULTI | |
OK | |
> SET PROJECT "JavaGuide" | |
QUEUED | |
> GET PROJECT | |
QUEUED | |
> EXEC | |
1) OK | |
2) "JavaGuide" |
MULTI 命令后可以输入多个命令,Redis 不会立即执行这些命令,而是将它们放到队列,当调用了 EXEC 命令后,再执行所有的命令。
这个过程是这样的:
- 开始事务(
MULTI); - 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行);
- 执行事务(
EXEC)。
你也可以通过 DISCARD 命令取消一个事务,它会清空事务队列中保存的所有命令。
> MULTI | |
OK | |
> SET PROJECT "JavaGuide" | |
QUEUED | |
> GET PROJECT | |
QUEUED | |
> DISCARD | |
OK |
你可以通过 WATCH 命令监听指定的 Key,当调用 EXEC 命令执行事务时,如果一个被 WATCH 命令监视的 Key 被 其他客户端 / Session 修改的话,整个事务都不会被执行。
# 客户端 1 | |
> SET PROJECT "RustGuide" | |
OK | |
> WATCH PROJECT | |
OK | |
> MULTI | |
OK | |
> SET PROJECT "JavaGuide" | |
QUEUED | |
# 客户端 2 | |
# 在客户端 1 执行 EXEC 命令提交事务之前修改 PROJECT 的值 | |
> SET PROJECT "GoGuide" | |
# 客户端 1 | |
# 修改失败,因为 PROJECT 的值被客户端 2 修改了 | |
> EXEC | |
(nil) | |
> GET PROJECT | |
"GoGuide" |
不过,如果 WATCH 与 事务 在同一个 Session 里,并且被 WATCH 监视的 Key 被修改的操作发生在事务内部,这个事务是可以被执行成功的(相关 issue:WATCH 命令碰到 MULTI 命令时的不同效果)。
事务内部修改 WATCH 监视的 Key:
> SET PROJECT "JavaGuide" | |
OK | |
> WATCH PROJECT | |
OK | |
> MULTI | |
OK | |
> SET PROJECT "JavaGuide1" | |
QUEUED | |
> SET PROJECT "JavaGuide2" | |
QUEUED | |
> SET PROJECT "JavaGuide3" | |
QUEUED | |
> EXEC | |
1) OK | |
2) OK | |
3) OK | |
127.0.0.1:6379> GET PROJECT | |
"JavaGuide3" |
事务外部修改 WATCH 监视的 Key:
> SET PROJECT "JavaGuide" | |
OK | |
> WATCH PROJECT | |
OK | |
> SET PROJECT "JavaGuide2" | |
OK | |
> MULTI | |
OK | |
> GET USER | |
QUEUED | |
> EXEC | |
(nil) |
Redis 官网相关介绍 https://redis.io/topics/transactions 如下:

# 特性
Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性:
- ** 原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成(commit),要么完全不起作用(rollback);
- ** 一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
- ** 隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- ** 持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
Redis 事务仅保证了数据的一致性(C),不具有像 DBMS 一样的 ACID 特性。
- 这组命令中的某些命令的执行失败不会影响其它命令的执行,不会引发回滚,因此不具备原子性(A)。
- 这组命令仅通过乐观锁机制实现了简单的隔离性,没有复杂的隔离级别(I)。
- 这组命令的执行结果是被写入到内存的,是否持久(D)取决于 Redis 的持久化策略,与事务无关。而且,Redis 的持久化策略也存在数据丢失的问题,更加没法保证持久性。
# 不具备原子性(A)
Redis 事务在运行错误的情况下,除了执行过程中出现错误的命令外,其他命令都能正常执行。并且,Redis 事务是不支持回滚(roll back)操作的。因此,Redis 事务其实是不满足原子性的。
Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis 开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis 开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
# 实现了简单的隔离性(I)
从 Redis 2.2 开始,允许以乐观锁的形式为 Redis 事务操作提供额外保证,其方式与 check-and-set (CAS)操作非常相似。稍后将对此进行记录,具体可见隔离机制。
# 无法保证持久性(D)
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
- 快照(snapshotting,RDB)
- 只追加文件(append-only file, AOF)
- RDB 和 AOF 的混合持久化 (Redis 4.0 新增)
与 RDB 持久化相比,AOF 持久化的实时性更好。在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( fsync 策略),它们分别是:
appendfsync always #每次有数据修改发生时都会调用 fsync 函数同步 AOF 文件,fsync 完成后线程返回,这样会严重降低 Redis 的速度 | |
appendfsync everysec #每秒钟调用 fsync 函数同步一次 AOF 文件 | |
appendfsync no #让操作系统决定何时进行同步,一般为 30 秒一次 |
AOF 持久化的 fsync 策略为 no、everysec 时都会存在数据丢失的情况。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
因此,Redis 事务的持久性也是没办法保证的。
# 异常处理
# 语法错误
当事务中的命令出现语法错误时,整个事务在 exec 执行时会被取消。

exec 的提示是 exec 被忽略,事务被取消,因为之前的错误。
此时访问 age 的值,发现其仍为 19,并没有变为事务中设置的 20。

# 执行异常
如果事务中的命令没有语法错误,但在执行过程中出现异常,该异常不会影响其它命令的执行。

以上事务中第 2 条命令在执行时出现异常。因为 score 并非是整型,无法被增加 20 的操作。但该异常并不会影响其前后命令的正确执行。查看 score 与 name 的值,发现是执行成功的结果。

# 隔离机制
# 为什么需要隔离机制
在并发场景下可能会出现多个客户端对同一个数据进行修改的情况。
例如:有两个客户端 C 左与 C 右, C 左需要申请 40 个资源, C 右需要申请 30 个资源。它们首先查看了当前拥有的资源数量,即 resources 的值。它们查看到的都是 50,都感觉资源数量可以满足自己的需求,于是修改资源数量,以占有资源。但结果却是资源出现了 “超卖” 情况。

为了解决这种情况,Redis 事务通过 **乐观锁机制** 实现了多线程下的执行隔离。
# 隔离的实现
Redis 通过 watch 命令再配合事务实现了多线程下的执行隔离。

以上两个客户端执行的时间顺序为:

当 C 左客户端在 exec 事务前发现其 watch 的数据发生了改动,则会打断事务执行。
# 🌟实现原理
其内部的执行过程如下:
当某一客户端对 key 执行了
watch后,系统就会为该 key 添加一个 version 乐观锁,并初始化 version。例如初值为 1.0。此后客户端 C 左将对该 key 的修改语句写入到了事务命令队列中,虽未执行,但其将该 key 的 value 值与 version 进行了读取并保存到了当前客户端缓存。此时读取并保存的是 version 的初值 1.0。
此后客户端 C 右对该 key 的值进行了修改,这个修改不仅修改了 key 的 value 本身,同时也增加了 version 的值,例如使其 version 变为了 2.0,并将该 version 记录到了该 key 信息中。
此后客户端 C 左执行 exec,开始执行事务中的命令。不过,其在执行到对该 key 进行修改的命令时,该命令首先对当前客户端缓存中保存的 version 值与当前 key 信息中的 version 值进行比较。如果缓存 version 小于 key 的 version,则说明客户端缓存的 key 的 value 已经过时,该写操作如果执行可能会破坏数据的一致性。所以该写操作不执行。
# Redis 事务 v.s 数据库事务
单独的隔离操作:Redis 的事务仅仅是保证事务里的操作会被连续独占的执行,redis 命令执行是单线程架构,在执行完事务内所有指令前,是不可能再去同时执行其他客户端的请求的
没有隔离级别的概念:因为事务提交前任何指令都不会被实际执行,也就不存在 “事务内的查询要看到事务里的更新,在事务外查询不能看到” 这种问题了
因此不存在 “三大读问题”:不可重复读、脏读、幻读
不保证原子性:Redis 的事务 **不保证原子性**,也就是不保证所有指令同时成功或同时失败,只有决定是否开始执行全部指令的能力,没有回滚能力
排它性:Redis 会保证一个事务内的命令依次执行,而不会被其它命令插入
# 如何解决 Redis 事务的缺陷
Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常类似。可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此, 严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。
如果想要让 Lua 脚本中的命令全部执行,必须保证语句语法和命令都是对的。
另外,Redis 7.0 新增了 Redis functions 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本。
# Redis 管道(pipeline)
Redis 管道 与 Redis 事务 之间的关系,类似于雷锋与雷峰塔的关系,Java 与 JavaScript 的关系,看上去相似,但实际没有任何关系!
# 引言
如何优化命令频繁往返造成的性能瓶颈?
Redis 是一种基于客户端 - 服务端模型以及请求 / 响应协议的 TCP 服务。一个请求会遵循以下步骤:
客户端向服务端发送命令(分四步:发送命令→命令排队→命令执行→返回结果),并监听 Socket 返回,通常以阻塞模式等待服务端响应。
服务端处理命令,并将结果返回给客户端。
上述两步的总耗时称为:Round Trip Time(即 RTT,数据包往返于两端的时间)。
如果同时需要执行大量的命令,那么就要等待上一条命令应答后再执行,这中间不仅仅多了 RTT(Round Time Trip),而且还频繁调用系统 IO,发送网络请求,同时需要 redis 调用多次 read () 和 write () 系统方法,系统方法会将数据从用户态转移到内核态,这样就会对进程上下文有比较大的影响了,性能不太好o(╥﹏╥)o

# 简介
通过 **批处理 Redis 命令** 来优化往返时间 RTT
Redis 管道 (pipeline):为了优化 RTT 往返时间,可以一次性打包发送多条命令给服务端,而无需等待对每个命令的响应。等待服务端依次处理完完毕后,通过一条响应一次性将结果返回,通过减少客户端与 redis 的通信次数来实现降低往返延时时间。pipeline 的实现原理是队列,先进先出特性就保证数据的顺序性。
是一种批处理命令的变种优化措施,类似 Redis 原生的批命令(例如 mget 和 mset)。

# 案例
- 将欲执行的命令全部写到一个 txt 文件中
- 将 txt 文件的内容传递给 Redis 的 pipe 参数

# 总结
# 管道 vs 原生批量操作命令
| 管道 | 原生批量命令 |
|---|---|
| 非原子性 | 原子性 |
| 支持批量执行不同命令 | 一次只能执行一种命令 |
| 服务端与客户端共同完成 | 服务端实现 |
# 管道 vs Redis 事务
| 管道 | Redis 事务 |
|---|---|
| 非原子性,pipeline 之间可以交错执行 | 可视为原子操作,但不满足原子性,虽然两个不同的事务不会同时运行 |
| 一次性发送多条命令到服务端,请求次数更少 | 需要逐条发送命令到服务端 |
| 非阻塞 | 会阻塞其他命令的执行 |
# 使用管道的注意事项
pipeline 缓冲的指令只是会依次执行,不保证原子性,如果执行中指令发生异常,将会继续执行后续的指令
与 Redis 事务发生命令的运行时异常类似,冤头债主,不会连坐
使用 pipeline 组装的命令个数不能太多(例如 10k),不然数据量过大客户端阻塞的时间可能过久,同时服务端此时也被迫回复一个队列答复,占用很多内存
# 🌟Redis 性能优化
除了下面介绍的内容之外,再推荐两篇不错的文章:
- 你的 Redis 真的变慢了吗?性能优化如何做 - 阿里开发者
- Redis 常见阻塞原因总结 - JavaGuide
# 使用批量操作减少网络传输
一个 Redis 命令的执行可以简化为以下 4 步:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
其中,第 1 步和第 4 步耗费时间之和称为 Round Trip Time (RTT, 往返时间) ,也就是数据在网络上传输的时间。
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在 read() 和 write() 系统调用),批量操作还可以减少 socket I/O 成本。这个在官方对 pipeline 的介绍中有提到:[https://redis.io/docs/manual/pipelining/ 。
# 原生批量操作命令
Redis 中有一些原生支持批量操作的命令,比如:
MGET(获取一个或多个指定 key 的值)、MSET(设置一个或多个指定 key 的值)HMGET(获取指定哈希表中一个或者多个指定字段的值)、HMSET(同时将一个或多个 field-value 对设置到指定哈希表中)、SADD(向指定集合添加一个或多个元素)- ……
不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 MGET 无法保证所有的 key 都在同一个 hash slot(哈希槽)上, MGET 可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
- 找到 key 对应的所有 hash slot;
- 分别向对应的 Redis 节点发起
MGET请求获取数据; - 等待所有请求执行结束,重新组装结果数据,保持跟入参 key 的顺序一致,然后返回结果。
如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
# 管道(pipeline)
参考前文 [Redis 管道](#Redis 管道(pipeline))
对于不支持批量操作的命令,我们可以利用 pipeline(流水线) 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 元素个数 (例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
与 MGET 、 MSET 等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 hash slot(哈希槽)上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
[pipeline 与原生批量操作命令的区别](# 管道 vs 原生批量操作命令)
[pipeline 与 Redis 事务的区别](# 管道 vs Redis 事务)
另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 Lua 脚本 。
# Lua 脚本
Lua 脚本同样支持批量操作多条命令,一段 Lua 脚本可以视作一条命令执行,可以看作是 原子操作 。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
并且,Lua 脚本中支持一些简单的逻辑处理,比如使用命令读取值并在 Lua 脚本中进行处理,这同样是 pipeline 所不具备的。
不过,Lua 脚本依然存在下面这些缺陷:
- 如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 hash slot(哈希槽)上。
# 大量 key 集中过期问题
我在前面提到过:对于过期 key,Redis 采用的是 定期删除 + 惰性删除 策略。
定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
下面是两种常见的解决方法:
- 给 key 设置 **随机过期时间**。
- 开启 lazy-free(惰性删除)。该特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
# 🌟bigkey(大 Key)
# bigkey 是什么
简单来说,如果 **一个 key 对应的 value 所占用的内存比较大**,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
- String 类型的 value 超过 1MB
- 复合类型(List、Hash、Set、Sorted Set 等)的 value 包含的元素超过 5000 个(不过,对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。

# bigkey 怎么产生的
bigkey 通常是由于下面这些原因产生的:
- 程序设计不当,比如直接使用 String 类型存储较大的文件对应的二进制数据。
- 对于业务的数据规模考虑不周到,比如使用集合类型的时候没有考虑到数据量的快速增长。
- 未及时清理垃圾数据,比如哈希中冗余了大量的无用键值对。
# bigkey 的危害
bigkey 除了会消耗更多的内存空间和带宽,还会对性能造成比较大的影响。
在 Redis 常见阻塞原因总结这篇文章中我们提到:大 key 还会造成阻塞问题。具体来说,主要体现在下面三个方面:
- 客户端超时阻塞:由于 Redis 执行命令是单线程处理,然后在操作大 key 时会比较耗时,那么就会阻塞 Redis,从客户端这一视角看,就是很久很久都没有响应。
- 网络阻塞:每次获取大 key 产生的网络流量较大,如果一个 key 的大小是 1 MB,每秒访问量为 1000,那么每秒会产生 1000MB 的流量,这对于普通千兆网卡的服务器来说是灾难性的。
- 工作线程阻塞:如果使用 del 删除大 key 时,会阻塞工作线程,这样就没办法处理后续的命令。
大 key 造成的阻塞问题还会进一步影响到主从同步和集群扩容。
综上,大 key 带来的潜在问题是非常多的,我们应该尽量避免 Redis 中存在 bigkey。
# 如何发现 bigkey
1、使用 Redis 自带的 --bigkeys 参数来查找
# redis-cli -p 6379 --bigkeys | |
# Scanning the entire keyspace to find biggest keys as well as | |
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec | |
# per 100 SCAN commands (not usually needed). | |
[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes | |
[00.00%] Biggest list found so far '"my-list"' with 17 items | |
-------- summary ------- | |
Sampled 5 keys in the keyspace! | |
Total key length in bytes is 264 (avg len 52.80) | |
Biggest list found '"my-list"' has 17 items | |
Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes | |
1 lists with 17 items (20.00% of keys, avg size 17.00) | |
0 hashs with 0 fields (00.00% of keys, avg size 0.00) | |
4 strings with 4831 bytes (80.00% of keys, avg size 1207.75) | |
0 streams with 0 entries (00.00% of keys, avg size 0.00) | |
0 sets with 0 members (00.00% of keys, avg size 0.00) | |
0 zsets with 0 members (00.00% of keys, avg size 0.00 |
从这个命令的运行结果,我们可以看出:这个命令会扫描 (Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 String 数据类型,包含元素最多的复合数据类型)。然而,一个 key 的元素多并不代表占用内存也多,需要我们根据具体的业务情况来进一步判断。
在线上执行该命令时,为了降低对 Redis 的影响,需要指定 -i 参数控制扫描的频率。 redis-cli -p 6379 --bigkeys -i 3 表示扫描过程中每次扫描后休息的时间间隔为 3 秒。
2、使用 Redis 自带的 SCAN 命令
SCAN 命令可以按照一定的模式、数量返回匹配的 key。获取了 key 之后,可以利用 STRLEN 、 HLEN 、 LLEN 等命令返回其长度或成员数量。
| 数据结构 | 命令 | 复杂度 | 结果(对应 key) |
|---|---|---|---|
| String | STRLEN | O(1) | 字符串值的长度 |
| Hash | HLEN | O(1) | 哈希表中字段的数量 |
| List | LLEN | O(1) | 列表元素数量 |
| Set | SCARD | O(1) | 集合元素数量 |
| Sorted Set | ZCARD | O(1) | 有序集合的元素数量 |
对于集合类型还可以使用 MEMORY USAGE 命令(Redis 4.0+),这个命令会返回键值对占用的内存空间。
3、借助开源工具分析 RDB 文件
通过分析 RDB 文件来找出 big key。这种方案的前提是你的 Redis 采用的是 RDB 持久化。
网上有现成的代码 / 工具可以直接拿来使用:
- redis-rdb-tools:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
- rdb_bigkeys : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
4、借助公有云的 Redis 分析服务
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
这里以阿里云 Redis 为例说明,它支持 bigkey 实时分析、发现,文档地址:https://www.alibabacloud.com/help/zh/apsaradb-for-redis/latest/use-the-real-time-key-statistics-feature 。

# 如何处理 bigkey
bigkey 的常见处理以及优化办法如下(这些方法可以配合起来使用):
- 分割 bigkey:将一个 bigkey 分割为多个小 key。例如,将一个含有上万字段数量的 Hash 按照一定策略(比如二次哈希)拆分为多个 Hash。
- 手动清理:Redis 4.0+ 可以使用
UNLINK命令来异步删除一个或多个指定的 key。Redis 4.0 以下可以考虑使用SCAN命令结合DEL命令来分批次删除。 - 采用合适的数据结构:例如,文件二进制数据不使用 String 保存、使用 HyperLogLog 统计页面 UV、Bitmap 保存状态信息(0/1)。
- 开启 lazy-free(惰性删除 / 延迟释放):lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
# hotkey(热 Key)
# hotkey 是什么
如果 **一个 key 的访问次数比较多且明显多于其他 key** ,那这个 key 就可以看作是 hotkey(热 Key)。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
hotkey 出现的原因主要是某个热点数据访问量暴增,如重大的热搜事件、参与秒杀的商品。
# hotkey 的危害
处理 hotkey 会占用大量的 CPU 和带宽,可能会影响 Redis 实例对其他请求的正常处理。此外,如果突然访问 hotkey 的请求超出了 Redis 的处理能力,Redis 就会直接宕机。这种情况下,大量请求将落到后面的数据库上,可能会导致数据库崩溃。
因此,hotkey 很可能成为系统性能的瓶颈点,需要单独对其进行优化,以确保系统的高可用性和稳定性。
# 如何发现 hotkey
1、使用 Redis 自带的 --hotkeys 参数来查找
Redis 4.0.3 版本中新增了 hotkeys 参数,该参数能够返回所有 key 的被访问次数。
使用该方案的前提条件是 Redis Server 的 maxmemory-policy 参数设置为 LFU 算法,不然就会出现如下所示的错误。
# redis-cli -p 6379 --hotkeys | |
# Scanning the entire keyspace to find hot keys as well as | |
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec | |
# per 100 SCAN commands (not usually needed). | |
Error: ERR An LFU maxmemory policy is not selected, access frequency not tracked. Please note that when switching between policies at runtime LRU and LFU data will take some time to adjust. |
Redis 中有两种 LFU 算法:
- volatile-lfu(least frequently used):从已设置过期时间的数据集(
server.db[i].expires)中挑选最不经常使用的数据淘汰。 - allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key。
以下是配置文件 redis.conf 中的示例:
# 使用 volatile-lfu 策略 | |
maxmemory-policy volatile-lfu | |
# 或者使用 allkeys-lfu 策略 | |
maxmemory-policy allkeys-lfu |
需要注意的是, hotkeys 参数命令也会增加 Redis 实例的 CPU 和内存消耗(全局扫描),因此需要谨慎使用。
2、使用 MONITOR 命令
MONITOR 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于实时监控 Redis 实例的操作情况,包括读写、删除等操作。
由于该命令对 Redis 性能的影响比较大,因此禁止长时间开启 MONITOR (生产环境中建议谨慎使用该命令)。
# redis-cli | |
127.0.0.1:6379> MONITOR | |
OK | |
1683638260.637378 [0 172.17.0.1:61516] "ping" | |
1683638267.144236 [0 172.17.0.1:61518] "smembers" "mySet" | |
1683638268.941863 [0 172.17.0.1:61518] "smembers" "mySet" | |
1683638269.551671 [0 172.17.0.1:61518] "smembers" "mySet" | |
1683638270.646256 [0 172.17.0.1:61516] "ping" | |
1683638270.849551 [0 172.17.0.1:61518] "smembers" "mySet" | |
1683638271.926945 [0 172.17.0.1:61518] "smembers" "mySet" | |
1683638274.276599 [0 172.17.0.1:61518] "smembers" "mySet2" | |
1683638276.327234 [0 172.17.0.1:61518] "smembers" "mySet" |
在发生紧急情况时,我们可以选择在合适的时机短暂执行 MONITOR 命令并将输出重定向至文件,在关闭 MONITOR 命令后通过对文件中请求进行归类分析即可找出这段时间中的 hotkey。
3、借助开源项目
京东零售的 hotkey 这个项目不光支持 hotkey 的发现,还支持 hotkey 的处理。

4、根据业务情况提前预估
可以根据业务情况来预估一些 hotkey,比如参与秒杀活动的商品数据等。不过,我们无法预估所有 hotkey 的出现,比如突发的热点新闻事件等。
5、业务代码中记录分析
在业务代码中添加相应的逻辑对 key 的访问情况进行记录分析。不过,这种方式会让业务代码的复杂性增加,一般也不会采用。
6、借助公有云的 Redis 分析服务
如果你用的是公有云的 Redis 服务的话,可以看看其是否提供了 key 分析功能(一般都提供了)。
这里以阿里云 Redis 为例说明,它支持 hotkey 实时分析、发现,文档地址:https://www.alibabacloud.com/help/zh/apsaradb-for-redis/latest/use-the-real-time-key-statistics-feature 。
# 如何解决 hotkey
hotkey 的常见处理以及优化办法如下(这些方法可以配合起来使用):
- 读写分离:主节点处理写请求,从节点处理读请求。
- 使用 Redis Cluster:将热点数据分散存储在多个 Redis 节点上。
- 二级缓存:hotkey 采用二级缓存的方式进行处理,将 hotkey 存放一份到 JVM 本地内存中(可以用 Caffeine)。
除了这些方法之外,如果你使用公有云的 Redis 服务话,还可以留意其提供的开箱即用的解决方案。
这里以阿里云 Redis 为例说明,它支持通过代理查询缓存功能(Proxy Query Cache)优化热点 Key 问题。

# 慢查询命令
# 慢查询命令的产生原因
我们知道一个 Redis 命令的执行可以简化为以下 4 步:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
Redis 慢查询统计的是命令执行这一步骤的耗时,慢查询命令也就是那些命令执行时间较长的命令。
Redis 为什么会有慢查询命令呢?[O (n) 命令](#O (n) 命令)
# 如何发现慢查询命令
在 redis.conf 文件中,我们可以使用 slowlog-log-slower-than 参数设置耗时命令的阈值,并使用 slowlog-max-len 参数设置耗时命令的最大记录条数。
当 Redis 服务器检测到执行时间超过 slowlog-log-slower-than 阈值的命令时,就会将该命令记录在 **慢查询日志 (slow log)** 中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数 slowlog-max-len 之后,Redis 会把最早的执行命令依次舍弃。
⚠️注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
slowlog-log-slower-than 和 slowlog-max-len 的默认配置如下 (可以自行修改):
# The following time is expressed in microseconds, so 1000000 is equivalent | |
# to one second. Note that a negative number disables the slow log, while | |
# a value of zero forces the logging of every command. | |
slowlog-log-slower-than 10000 | |
# There is no limit to this length. Just be aware that it will consume memory. | |
# You can reclaim memory used by the slow log with SLOWLOG RESET. | |
slowlog-max-len 128 |
除了修改配置文件之外,你也可以直接通过 CONFIG 命令直接设置:
# 命令执行耗时超过 10000 微妙(即 10 毫秒)就会被记录 | |
CONFIG SET slowlog-log-slower-than 10000 | |
# 只保留最近 128 条耗时命令 | |
CONFIG SET slowlog-max-len 128 |
获取慢查询日志的内容很简单,直接使用 SLOWLOG GET 命令即可。
127.0.0.1:6379> SLOWLOG GET #慢日志查询 | |
1) 1) (integer) 5 | |
2) (integer) 1684326682 | |
3) (integer) 12000 | |
4) 1) "KEYS" | |
2) "*" | |
5) "172.17.0.1:61152" | |
6) "" | |
// ... |
慢查询日志中的每个条目都由以下六个值组成:
- 唯一渐进的日志标识符。
- 处理记录命令的 Unix 时间戳。
- 执行所需的时间量,以微秒为单位。
- 组成命令参数的数组。
- 客户端 IP 地址和端口。
- 客户端名称。
SLOWLOG GET 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 SLOWLOG GET N 。
下面是其他比较常用的慢查询相关的命令:
# 返回慢查询命令的数量 | |
127.0.0.1:6379> SLOWLOG LEN | |
(integer) 128 | |
# 清空慢查询命令 | |
127.0.0.1:6379> SLOWLOG RESET | |
OK |
# Redis 内存碎片
# 内存碎片是什么
可以将内存碎片简单地理解为那些不可用的空闲内存。
举个例子:操作系统为你分配了 32 字节的连续内存空间,而你存储数据实际只需要使用 24 字节内存空间,那这多余出来的 8 字节内存空间如果后续没办法再被分配存储其他数据的话,就可以被称为内存碎片。

Redis 内存碎片虽然不会影响 Redis 性能,但是会增加内存消耗。
# Redis 内存碎片的产生原因
Redis 内存碎片产生比较常见的 2 个原因:
1、Redis 存储数据时,向操作系统申请的内存空间可能会大于数据实际需要的存储空间。
Redis 使用 zmalloc 方法(Redis 自己实现的内存分配方法) 进行内存分配的时候,除了要分配 size 大小的内存之外,还会多分配 PREFIX_SIZE 大小的内存。
zmalloc方法源码如下(源码地址:https://github.com/antirez/redis-tools/blob/master/zmalloc.c)
void *zmalloc(size_t size) { | |
// 分配指定大小的内存 | |
void *ptr = malloc(size+PREFIX_SIZE); | |
if (!ptr) zmalloc_oom_handler(size); | |
#ifdef HAVE_MALLOC_SIZE | |
update_zmalloc_stat_alloc(zmalloc_size(ptr)); | |
return ptr; | |
#else | |
*((size_t*)ptr) = size; | |
update_zmalloc_stat_alloc(size+PREFIX_SIZE); | |
return (char*)ptr+PREFIX_SIZE; | |
#endif | |
} |
另外,Redis 可以使用多种内存分配器(libc、jemalloc、tcmalloc)来分配内存,默认使用 jemalloc。而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节……)来分配内存的。jemalloc 划分的内存单元如下图所示:

当程序申请的内存最接近某个固定值时,jemalloc 会给它分配相应大小的空间。就比如说程序需要申请 17 字节的内存,jemalloc 会直接给它分配 32 字节的内存,这样会导致有 15 字节内存的浪费。不过,jemalloc 专门针对内存碎片问题做了优化,一般不会存在过度碎片化的问题。
2、频繁修改 Redis 中的数据也会产生内存碎片。
当 Redis 中的某个数据删除时,Redis 通常不会轻易释放内存给操作系统。
这个在 Redis 官方文档中也有对应的原话:

文档地址:https://redis.io/topics/memory-optimization 。
# 如何查看 Redis 内存碎片的信息
使用 info memory 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:https://redis.io/commands/INFO 。

Redis 内存碎片率的计算公式: mem_fragmentation_ratio (内存碎片率)= used_memory_rss (操作系统实际分配给 Redis 的物理内存空间大小)/ used_memory (Redis 内存分配器为了存储数据实际申请使用的内存空间大小)
也就是说, mem_fragmentation_ratio (内存碎片率)的值越大代表内存碎片率越严重。
一定不要误认为 used_memory_rss 减去 used_memory 值就是内存碎片的大小!!!这不仅包括内存碎片,还包括其他进程开销,以及共享库、堆栈等的开销。
很多小伙伴可能要问了:“多大的内存碎片率才是需要清理呢?”。
通常情况下,我们认为 mem_fragmentation_ratio > 1.5 的话才需要清理内存碎片。 mem_fragmentation_ratio > 1.5 意味着你使用 Redis 存储实际大小 2G 的数据需要使用大于 3G 的内存。
如果想要快速查看内存碎片率的话,你还可以通过下面这个命令:
> redis-cli -p 6379 info | grep mem_fragmentation_ratio |
另外,内存碎片率可能存在小于 1 的情况。这种情况我在日常使用中还没有遇到过,感兴趣的小伙伴可以看看这篇文章 故障分析 | Redis 内存碎片率太低该怎么办?- 爱可生开源社区 。
# 如何清理 Redis 内存碎片?
Redis4.0-RC3 版本以后自带了内存整理,可以避免内存碎片率过大的问题。
直接通过 config set 命令将 activedefrag 配置项设置为 yes 即可。
config set activedefrag yes |
具体什么时候清理需要通过下面两个参数控制:
# 内存碎片占用空间达到 500mb 的时候开始清理 | |
config set active-defrag-ignore-bytes 500mb | |
# 内存碎片率大于 1.5 的时候开始清理 | |
config set active-defrag-threshold-lower 50 |
通过 Redis 自动内存碎片清理机制可能会对 Redis 的性能产生影响,我们可以通过下面两个参数来减少对 Redis 性能的影响:
# 内存碎片清理所占用 CPU 时间的比例不低于 20% | |
config set active-defrag-cycle-min 20 | |
# 内存碎片清理所占用 CPU 时间的比例不高于 50% | |
config set active-defrag-cycle-max 50 |
另外,重启节点可以做到内存碎片重新整理。如果你采用的是高可用架构的 Redis 集群的话,你可以将碎片率过高的主节点转换为从节点,以便进行安全重启。
# 🌟Redis 生产问题(高并发问题)
# 缓存穿透
# 是什么
缓存穿透说简单点就是 **大量请求的 key 既不存在于缓存中,也不存在于数据库中,进行了两次无用的查询,最终返回空数据**。这就导致这些请求直接到了数据库上,根本没有经过缓存这一层,对数据库造成了巨大的压力,可能直接就被这么多请求弄宕机了。

举个例子:某个黑客故意制造一些非法的 key 发起大量请求,导致大量请求落到数据库,结果数据库上也没有查到对应的数据。也就是说这些请求最终都落到了数据库上,对数据库造成了巨大的压力。
# 如何解决
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
# 1)缓存无效 key
将缓存和数据库都查不到某个 key 的数据写到 Redis 中,并设置过期时间。具体命令如下: SET key value EX 10086 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: 表名:列名:主键名:主键值 。
如果用 Java 代码展示的话,差不多是下面这样的:
public Object getObjectInclNullById(Integer id) { | |
// 从缓存中获取数据 | |
Object cacheValue = cache.get(id); | |
// 缓存为空 | |
if (cacheValue == null) { | |
// 从数据库中获取 | |
Object storageValue = storage.get(key); | |
// 缓存空对象 | |
cache.set(key, storageValue); | |
// 如果存储数据为空,需要设置一个过期时间 (300 秒) | |
if (storageValue == null) { | |
// 必须设置过期时间,否则有被攻击的风险 | |
cache.expire(key, 60 * 5); | |
} | |
return storageValue; | |
} | |
return cacheValue; | |
} |
# 2)布隆过滤器
常用方法
布隆过滤器是一个非常神奇的数据结构,它将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被拦截掉,从而避免了对底层存储系统的查询压力。通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个 “人”。
具体是这样做的:把所有可能存在的请求值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
加入布隆过滤器之后的缓存处理流程图如下:

但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是:布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。
为什么会出现误判的情况呢?我们还要从布隆过滤器的原理来说!
我们先来看一下,当一个元素加入布隆过滤器中的时候,会进行哪些操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
我们再来看一下,当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:
- 对给定元素再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
然后,一定会出现这样一种情况:不同的字符串可能哈希出来的位置相同。 (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
更多关于布隆过滤器的内容可以看我的这篇原创:《不了解布隆过滤器?一文给你整的明明白白!》 ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
# 缓存击穿
# 是什么
缓存击穿是指,一个缓存中的数据因为某种原因只存在于数据库中,不存在于缓存中,然后在短时间内遭受大量的请求(热点数据),导致这些请求直接穿透到数据库或其他后端存储系统,增加了后端系统的负载。
举个例子:秒杀进行过程中,缓存中的某个秒杀商品的数据突然过期,这就导致瞬时大量对该商品的请求直接落到数据库上,对数据库造成了巨大的压力。
缓存击穿通常在以下情况下发生:
- 热点数据的 key 过期 / 被删除:当缓存中存储的热门数据过期 / 被删除时,大量的请求会同时查询后端数据库。
- 第一次请求:对于一个之前从未被请求过的数据,当它第一次被请求时,缓存中没有这个数据,从而导致请求穿透到后端存储。


# 如何解决
为了解决 Redis 缓存击穿问题,可以采取以下常见的方案:
- 提前预热热点数据,并设置合理的过期时间:例如永不过期 / 较长的过期时间,确保数据可以从缓存中获取,后续再手动删除。
- 使用分布式锁:在获取数据时,使用分布式锁(如 Redis 的分布式锁)来控制同时只有一个请求可以去后端获取数据,其他请求需要等待锁释放。这样可以防止多个请求同时穿透到后端存储。
设置热点数据永不过期属于是业务范围应该考虑的事情,这个数据是否应该永不过期?或者说活动时设置过期时间为 -1,活动后再执行程序删除。有一点可以确认,缓存数据不可能全部都是永不过期,因为缓存的存储压力会比较大,所以方案 1 无法作为通用方案。
# 缓存穿透与缓存击穿的区别
缓存穿透中,请求的 key 既不存在于缓存中,也不存在于数据库中。
缓存击穿中,请求的 key 对应的是 热点数据 ,该数据 存在于数据库中,但不存在于缓存中(通常是因为缓存中的那份数据已经过期) 。
# 缓存雪崩
# 是什么
实际上,缓存雪崩描述的就是这样一个简单的场景:**缓存在同一时间大面积失效,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。** 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
另外,缓存服务宕机也会导致缓存雪崩现象,导致所有的请求都落到了数据库上。

举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
# 如何解决
针对热点缓存失效的情况:
- 设置不同的失效时间,比如随机设置缓存的失效时间。
- 缓存永不失效(不太推荐,实用性太差)。
- 设置二级缓存。
针对 Redis 服务不可用的情况:
- 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
- 限流,避免同时处理大量的请求。
# 缓存雪崩与缓存击穿的区别
缓存雪崩和缓存击穿比较像,但导致缓存雪崩的原因是缓存中的大量或者所有数据失效,导致缓存击穿的原因主要是某个热点数据不存在于缓存中(通常是因为缓存中的那份数据已经过期)。
# 如何保证缓存和数据库数据的一致性?
个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
- 缩短缓存失效时间(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
- 增加 cache 更新重试机制(常用):如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
相关文章推荐:缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹。
# Redis 阻塞的常见原因
# O (n) 命令
Redis 中的大部分命令都是 O (1) 时间复杂度,但也有少部分 O (n) 时间复杂度的命令,例如:
KEYS *:会返回所有符合规则的 key。HGETALL:会返回一个 Hash 中所有的键值对。LRANGE:会返回 List 中指定范围内的元素。SMEMBERS:返回 Set 中的所有元素。SINTER/SUNION/SDIFF:计算多个 Set 的交集 / 并集 / 差集。- ……
由于这些命令时间复杂度是 O (n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长。不过,这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 HSCAN 、 SSCAN 、 ZSCAN 代替。
除了这些 O (n) 时间复杂度的命令可能会导致慢查询之外, 还有一些时间复杂度可能在 O (N) 以上的命令,例如:
ZRANGE/ZREVRANGE:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O (log (n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O (n) 的时间复杂度更小。ZREMRANGEBYRANK/ZREMRANGEBYSCORE:移除 Sorted Set 中指定排名范围 / 指定 score 范围内的所有元素。时间复杂度为 O (log (n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O (n) 的时间复杂度更小。- ……
# SAVE 创建 RDB 快照
Redis 提供了两个命令来生成 RDB 快照文件:
save: 同步保存操作,会阻塞 Redis 主线程;bgsave: fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
默认情况下,Redis 默认配置会使用 bgsave 命令。如果手动使用 save 命令生成 RDB 快照文件的话,就会阻塞主线程。
# AOF
# AOF 日志记录阻塞
AOF 持久化机制是在执行完命令之后再记录日志,这和关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复)不同。
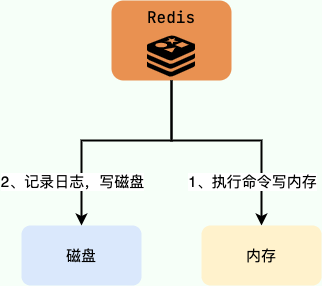
为什么是在执行完命令之后记录日志呢?
- 避免额外的命令语法检查开销,AOF 记录日志不会对命令进行语法检查;
- 在命令执行完之后再记录,不会阻塞当前的命令执行。
这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
- 如果刚执行完命令 Redis 就宕机,会导致对应的修改丢失;
- 由于 AOF 记录日志是在 Redis 主线程中进行的,因此可能会阻塞后续其他命令的执行。
# AOF 刷盘阻塞
开启 AOF 持久化后,Redis 会将每条执行的写命令写入到 AOF 缓冲区 server.aof_buf 中,然后再根据 appendfsync 配置参数来决定何时将其同步到硬盘中的 AOF 文件(刷盘)。
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( fsync 策略):
always:主线程调用write执行写操作后,后台线程(aof_fsync线程)立即会调用fsync函数同步 AOF 文件(刷盘),fsync完成后线程返回,这样会严重降低 Redis 的性能(write+fsync)。everysec:主线程调用write执行写操作后立即返回,由后台线程(aof_fsync线程)每秒钟调用fsync函数(系统调用)同步一次 AOF 文件(write+fsync,fsync间隔为 1 秒)no:主线程调用write执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(write但不fsync,fsync的时机由操作系统决定)。
当后台线程( aof_fsync 线程)调用 fsync 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 fsync 操作发生阻塞,主线程调用 write 函数时也会被阻塞。 fsync 完成后,主线程执行 write 才能成功返回。
关于 AOF 工作流程的详细介绍可以查看:[AOF 持久化](#AOF 持久化),有助于理解 AOF 刷盘阻塞。
# AOF 重写阻塞
- 主线程 fork 出一条子线程来将文件重写,在执行
BGREWRITEAOF命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子线程创建新 AOF 文件期间,记录服务器执行的所有写命令。 - 当子线程完成创建新 AOF 文件的工作之后,服务器会将 AOF 重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
- 最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
阻塞就是出现在第 2 步的过程中,将 AOF 重写缓冲区中的新数据写到新 AOF 文件的过程中会产生阻塞。
相关阅读:Redis AOF 重写阻塞问题分析。
# bigkey
[bigkey 是什么](#bigkey 是什么)
[bigkey 的危害](#bigkey 的危害)
# 查找 bigkey
[如何发现 bigkey](# 如何发现 bigkey)
当我们在使用 Redis 自带的 --bigkeys 参数查找大 key 时,最好选择在从节点上执行该命令,因为主节点上执行时,会阻塞主节点。
- 我们还可以使用
SCAN命令来查找大 key; - 通过分析 RDB 文件来找出 big key,这种方案的前提是 Redis 采用的是 RDB 持久化。网上有现成的工具:
- redis-rdb-tools:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
- rdb_bigkeys:Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
# 删除 bigkey
删除操作的本质是要释放键值对占用的内存空间。
释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,操作系统需要把释放掉的内存块插入一个空闲内存块的链表,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会 **阻塞** 当前释放内存的应用程序。
所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
删除大 key 时建议采用分批次删除和异步删除的方式进行。
# 清空数据库
清空数据库和上面 bigkey 删除也是同样道理, flushdb 、 flushall 也涉及到删除和释放所有的键值对,也是 Redis 的阻塞点。
# 集群扩容、缩容
Redis 集群可以进行节点的动态扩容、缩容,这一过程目前还处于半自动状态,需要人工介入。
在扩缩容的时候,需要进行数据迁移。而 Redis 为了保证迁移的一致性,迁移所有操作都是同步操作。
执行迁移时,两端的 Redis 均会进入时长不等的阻塞状态,对于小 Key,该时间可以忽略不计,但如果一旦 Key 的内存使用过大,严重的时候会触发集群内的故障转移,造成不必要的切换。
# Swap(内存交换)
Linux 中的 Swap 常被称为内存交换。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
Swap 对于 Redis 来说是非常致命的,因为 Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘的读写速度差几个数量级,会导致发生交换后的 Redis 性能急剧下降。
识别 Redis 发生 Swap 的检查方法如下:
1、查询 Redis 进程号
reids-cli -p 6383 info server | grep process_id | |
process_id: 4476 |
2、根据进程号查询内存交换信息
cat /proc/4476/smaps | grep Swap | |
Swap: 0kB | |
Swap: 0kB | |
Swap: 4kB | |
Swap: 0kB | |
Swap: 0kB | |
..... |
如果交换量都是 0KB 或者个别的是 4KB,则正常。
预防内存交换的方法:
- 保证机器充足的可用内存
- 确保所有 Redis 实例设置最大可用内存 (maxmemory),防止极端情况 Redis 内存不可控的增长
- 降低系统使用 swap 优先级,如
echo 10 > /proc/sys/vm/swappiness
# CPU 竞争
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
可以通过 reids-cli --stat 获取当前 Redis 使用情况。通过 top 命令获取进程对 CPU 的利用率等信息,通过 info commandstats 统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
# 网络问题
连接拒绝、网络延迟,网卡软中断等网络问题也可能会导致 Redis 阻塞。
# Redis 发布订阅(pub/sub)
这是 Redis 的第一代消息中间件,第二代是 Stream,然而一般使用的都是更加成熟的第三方消息中间件。
了解即可,实际工作中用的很少,一般都是将 Redis 用作分布式缓存。
# 消息系统
发布 / 订阅,即 pub/sub,是一种消息通信模式:发布者也称为消息生产者,生产和发送消息到存储系统;订阅者也称为消息消费者,从存储系统接收和消费消息。这个存储系统可以是文件系统 FS、消息中间件 MQ、数据管理系统 DBMS,也可以是 Redis。整个消息发布者、订阅者、存储系统称为消息系统。

消息系统中的订阅者订阅了某类消息后,只要存储系统中存在该类消息,其就可不断的接收并消费这些消息。当存储系统中没有该消息后,订阅者的接收、消费阻塞。而当发布者将消息写入到存储系统后,会立即唤醒订阅者。当存储系统放满时,不同的发布者具有不同的处理方式:有的会阻塞发布者的发布,等待可用的存储空间;有的则会将多余的消息丢失。
当然,不同的消息系统消息的发布 / 订阅方式也是不同的。例如 RocketMQ、 Kafka 等消息中间件构成的消息系统中,发布 / 订阅的消息都是以主题 Topic 分类的。而 Redis 构成的消息系统中,发布 / 订阅的消息都是以频道 Channel 分类的。
# pub/sub 简介
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者 (PUBLISH) 发送消息,订阅者 (SUBSCRIBE) 接收消息,可以实现进程间的消息传递。
一言蔽之:Redis 可以通过发布订阅实现消息的引导和分流,实现消息中间件 MQ 的功能。但是不推荐使用该功能,专业的事情交给专业的中间件处理,redis 就做好分布式缓存功能。


小结:发布 / 订阅其实是一个轻量的队列,只不过数据不会被持久化,一般用来处理实时性较高的异步消息。

# 相关命令
| 命令 | 介绍 |
|---|---|
PUBLISH channel message | 发布一个频道的消息。返回值为接收到该消息的订阅者数量。 |
SUBSCRIBE channel [channel ...] | 同时订阅任意数量的 channel。在输出了订阅了主题后,命令处于阻塞状态,等待相关 channel 的消息。 |
PSUBSCRIBE pattern [pattern …] | 订阅一个或多个符合给定模式 pattern 的频道 channel。这里的 pattern 只能使用通配符 *。例如,it* 可以匹配所有以 it 开头的频道,像 it.news、it.blog、 it.tweets 等;news.* 可以匹配所有以 news. 开头的频道,像 news.global.today、news.it 等。 |
UNSUBSCRIBE [channel [channel …]] | 退订指定的频道。如果没有频道被指定,也就是一个无参数的 UNSUBSCRIBE 命令被执行,那么客户端使用 SUBSCRIBE 命令订阅的所有频道都会被退订。在这种情况下,命令会返回一个信息,告知客户端所有被退订的频道。 |
PUNSUBSCRIBE [channel [channel …]] | 退订一个或多个符合给定模式的频道。这里的 pattern 也只能使用通配符 *。 |
PUBSUB <subcommand> [argument [argument …]] | PUBSUB 是一个查看订阅与发布系统状态的内省命令集,它由数个不同格式的子命令组成。 |
# 缺点
在 Redis 系统中 **发布的消息不能持久化**。因此,必须先执行订阅,再等待消息发布。如果先发布了消息,那么该消息由于没有订阅者,消息将被直接丢弃。
消息只管发送,对于发布者而言消息是即发即失的,不管接收,也 **没有 ACK 机制**,无法保证消息的消费成功。
以上的缺点导致 **Redis 的 Pub/Sub 模式就像个小玩具**,在生产环境中几乎无用武之地。
为此 Redis5.0 版本新增了 Stream 数据结构,不但支持多播,还支持数据持久化,相比 Pub/Sub 更加的强大,但是也不推荐使用。
# 🌟Redis 集群(高可用)
Redis 为了支持高可用(HA),有 2 套机制:
- 主从复制(replica)+ 哨兵(sentinel)
- 集群(cluster)
为了避免 Redis 的单点故障问题,我们可以搭建一个 Redis 集群,将数据备份到集群中的其它节点上。若一个 Redis 节点宕机,则由集群中的其它节点顶上。
# 主从复制(replica)
# 是什么
承上启下的一节,前文都是在单机场景下,从此开始介绍多台 Redis 机器的场景,即通过主从复制支持多可用性、故障转移。
Redis 的主从集群是一个“一主多从” 的读写分离集群。集群中的 Master 节点负责处理客户端的读写请求,而 Slave 节点仅能处理客户端的读请求。之所以要将集群搭建为读写分离模式,主要原因是,对于数据库集群,写操作压力一般都较小,压力大多数来自于读操作请求。所以,只有一个节点负责处理写操作请求即可。
当 Master 节点上的数据变化时,会自动将新数据异步复制到其他 Slave 节点上。
# 作用
Redis 主从复制(replica)的功能如下:
- 读写分离
- 容灾恢复
- 数据备份
- 水平扩容,支撑高并发
# 基本命令
INFO replication:以一种易于理解和阅读的格式,返回关于当前 Redis 服务器的直接主 / 从复制信息REPLICAOF masterIp masterPort:修改当前 Redis 服务器的主 / 从复制设置(自动配置)一般写入进 redis.conf 配置文件内
SLAVEOF masterIp masterPort:将当前 Redis 服务器转变为指定服务器的从属服务器(手动配置)- 每次与 master 断开之后,都需要重新连接,除非你配置进 redis.conf 文件
- 在运行期间修改 slave 节点的信息,如果该数据库已经是某个主数据库的从数据库,那么会停止和原主数据库的同步关系,转而和新的主数据库同步,改换门庭
SLAVEOF NO ONE:将使得这个从属服务器关闭复制功能,并从从属服务器转回主服务器,自立为王,同时原来同步所得的数据集不会被丢弃。
# 常用的 3 招
配置方法:配从不配主
master 如果配置了
requirepass参数,需要密码登陆那么 slave 就要配置
masterauth来设置校验密码,否则 master 会拒绝 slave 的访问请求

# 一主二从

# 方案 1:配置文件固定写死
配从(6380 和 6381)不配主
![image-20230807193239828]()
依次启动 master 和两台 slave
![image-20230807193418057]()
查看主从关系
通过日志文件:通过
vim 6379.log查看 master 日志,通过vim 6380/6381.log查看 slave 日志![image-20230807193701621]()
master日志 ![image-20230807193733743]()
slave日志 通过命令:
info relication![image-20230807193843707]()
master的主从复制信息 ![image-20230807193915854]()
slave的主从复制信息






# 主从复制问题演示
问题 1:slave 不能执行写命令!
![image-20230807194936720]()
问题 2:slave 切入点问题。当某台 slave shutdown 并重启后,slave 对 master 首次进行全量复制,然后进行增量复制。
![image-20230807194924560]()
问题 3:master shutdown 后,slave 原地待命,数据仍可以正常使用,slave 等待 master 重启归来!
问题 4:shutdown 后的 master 重启归来,主从关系还在!slave 还能顺利复制!


# 方案 2:命令操作手动指定
slave 停机并去掉配置项,清空主从关系。此时 3 机都是 master,互不从属。
在预设的 2 个 slave 上执行命令
SLAVEOF masterIp masterHost指定 master
这种情况下,若 slave shutdown 并重启,主从关系就不存在了(因为没有设置配置文件)!

# 配置 vs 命令
配置(即方案 1)持久稳定,命令(即方案 2)临时生效。
# 薪火相传

要点:
- slave(6380)也可以作为其他 slave(6381)的 master,接收其连接和同步请求,可以有效减轻主 master(6379)的写压力。
- 改变 master 的命令:
SLAVEOF newMasterIp newMasterPort - slave(6380)仍然无法执行写命令!
- slave(6381)中途变更转向,master 从 6379 变为 6380,会清除之前 master(6379)的数据,重新建立拷贝新的 master(6380)的数据。
# 自立为王
slave 转成 master
命令 SLAVEOF NO ONE :停止与其他数据库的同步,清空数据,转成 Master 数据库。
# 一主二从的案例演示
# 架构说明
一主二从,一个 master,两个 slave,示意图如下:

拷贝多份配置文件,分别命名为:
- redis6379.conf
- redis6380.conf
- redis6381.conf
# 口诀
前提:三边网络互相 ping 通,同时注意防火墙配置。
三大命令:
- 主从复制:
REPLICAOF masterIp masterPort,配从不配主 - 改换门庭:
SLAVEOF masterIp masterPort - 自立为王:
SLAVEOF NO ONE
# 修改配置文件的操作细节
以 redis6379.conf 为例,步骤如下:
要求 Redis 后台运行,不要弹出命令行窗口:
daemonize yes取消 IP 的绑定,否则影响远程 IP 连接,注释掉
bind 127.0.0.1关闭保护模式,否则影响远程访问 / 连接:
protected-mode no指定端口:
port 6379指定当前工作目录,
dir /myredis设置 pid(进程 id)文件的路径和名字:
pidfile /var/run/redis_6379.pid设置 log 文件的路径和名字:
logfile "/myredis/6379.log"设置 Redis 服务器的密码:
requirepass 111111master、slave 均配置
设置 rdb 文件的名称:
dbfilename dump6379.rdb若开启 AOF,还需设置 aof 文件的名字:appendfilename 。这里不开启了。
slave 设置所访问的 master 的 IP 和端口:
replicaof masterIp 6379,并设置通行密码masterauth "111111"slave 需要配置
# 🌟原理(工作流程)

slave 首次连接,请求完全同步(sync):slave 首次连接 master 后会发送一个
sync命令,请求完全同步(全量复制)执行一次完全同步(全量复制),slave 自身原有数据会被覆盖清除
master 保存 RDB 快照,同时缓存写命令,响应给所有 slave 进行初始化(完全同步):
- master 节点收到
sync命令后会开始在后台保存快照(即 RDB 持久化,主从复制时会触发 RDB),同时缓存所有接收到的写命令,master 节点执行 RDB 持久化完后,master 将 rdb 快照文件和所有缓存的写命令发送到所有 slave,以完成一次完全同步 - 而 slave 服务在接收到数据库文件数据后,将其存盘并加载到内存中,从而完成复制初始化
- master 节点收到
心跳持续,保持通信:master 向 slave 发出 PING 包,周期默认 10 秒。
![image-20230807205137957]()
进入平稳,增量复制:master 继续将新的所有收集到的写命令自动依次传给 slave,完成同步
slave 下线,重连续传:假设某台 slave 宕机并重启了,master 会检查 backlog 里面的
offset,master 和 slave 都会保存一个复制的offset和一个 masterId,offset是保存在 backlog 中的。master 只会把已经复制的offset后面的数据复制给 slave,类似 **断点续传**。

# 分级管理
若 Redis 主从集群中的 Slave 较多时,它们的数据同步过程会对 Master 形成较大的性能压力。此时可以对这些 Slave 进行分级管理。

设置方式很简单,只需要 **让低级别 Slave 指定其 slaveof 的主机为其上一级 Slave 即可**。不过,上一级 Slave 的状态仍为 Slave,只不过,其是更上一级的 Slave。
例如,指定 6382 主机为 6381 主机的 Slave,而 6381 主机仍为真正的 Master 的 Slave。

此时会发现, Master 的 Slave 只有 6381 一个主机。
# 容灾冷处理
在 Master/Slave 的 Redis 集群中,若 Master 出现宕机怎么办呢?有两种处理方式:
- 冷处理:手工角色调整,使 Slave 晋升为 Master
- 热处理(哨兵模式):实现 Redis 集群的高可用 HA
无论 Master 是否宕机,Slave 都可通过 slaveof no one 将自己由 Slave 晋升为 Master。如果其原本就有下一级的 Slave,那么,其就直接变为了这些 Slave 的真正的 Master 了。而原来的 Master 也会失去这个原来的 Slave。

# 缺点
复制(同步)延时
由于所有的写操作都是先在 Master 上操作,然后同步更新到 Slave 上,所以从 Master 同步到 Slave 机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave 机器数量的增加也会使这个问题更加严重。
![image-20230807210259342]()
Master 宕机后群龙无首!默认情况下,不会从 slave 中重选一个 master,系统会陷入半瘫痪状态(只能读取,不能写入)那客户端的写命令如何执行啊?
期待有一种高可用的备份、恢复机制,能够从剩下的 slave 中选出一个 master!(无人值守安装:哨兵!)

# 哨兵机制(sentinel)
目的:为了实现主从集群中的 **自动化的故障转移**!
普通的主从复制方案下,一旦 master 宕机,我们需要从 slave 中手动选择一个新的 master,同时需要修改应用方的主节点地址,还需要命令所有从节点去复制新的主节点,整个过程需要人工干预。人工干预大大增加了问题的处理时间以及出错的可能性。
我们可以借助 Redis 官方的 Sentinel(哨兵)方案来帮助我们解决这个痛点,实现自动化的故障转移。
# 是什么
Redis Sentinel 实现 Redis 集群高可用,只是在主从复制实现集群的基础下,多了一个 Sentinel 角色来帮助我们监控 Redis 节点的运行状态,并自动实现故障转移。
当 master 节点出现故障的时候,Sentinel 会自动根据一定的规则选出一个 slave 升级为 master,从而实现自动化的故障转移,确保整个 Redis 系统的高可用性(HA)。整个过程完全自动,不需要人工介入。

# 作用
Sentinel 节点的功能如下:
- 监控:Sentinel 可以监控所有 Redis 节点(包括 Sentinel 节点自身)的状态是否正常。
- 故障转移:如果一个 master 出现故障,Sentinel 会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。
- 消息通知:通知 slave 新的 master 连接信息,让它们执行 replicaof 成为新的 master 的 slave。
- 配置中心:客户端通过连接 sentinel 来获得 master 的地址,如果发生故障转移,sentinel 会通知新的 master 链接信息给客户端。
Sentinel 本身设计的就是一个分布式系统,建议多个 sentinel 节点协作运行,好处是:
- 多个 sentinel 节点通过投票的方式来确定 master 节点是否真的不可用,避免误判(比如网络问题可能会导致误判)。
- Sentinel 自身就是高可用。
# Sentinel 配置文件(sentinel.conf)
默认在 /opt/redis-7.0.0 目录下
Sentinel(哨兵)只是 Redis 的一种运行模式,不提供读写服务,默认运行在 26379 端口上,依赖于 Redis 工作。
Redis 在 Sentinel 这种特殊的运行模式下,使用专门的命令表,也就是说普通模式运行下的 Redis 命令将无法使用。
通过下面的命令就可以让 Redis 以 Sentinel 的方式运行:
redis-sentinel /path/to/sentinel.conf | |
或者 | |
redis-server /path/to/sentinel.conf --sentinel |
Redis 源码中的 sentinel.conf 文件是用来配置 Sentinel 的,一个常见的最小配置如下所示:
// 指定要监视的 master | |
// 127.0.0.1 6379 为 master 地址 | |
// 2 表示当有 2 个 sentinel 认为 master 失效时,master 才算真正失效 | |
sentinel monitor mymaster 127.0.0.1 6379 2 | |
//master 节点宕机多长时间才会被 sentinel 认为是失效 | |
sentinel down-after-milliseconds mymaster 60000 | |
sentinel failover-timeout mymaster 180000 | |
sentinel parallel-syncs mymaster 1 | |
sentinel monitor resque 192.168.1.3 6380 4 | |
sentinel down-after-milliseconds resque 10000 | |
sentinel failover-timeout resque 180000 | |
// 在发生主备切换时最多可以有 5 个 slave 同时对新的 master 进行同步 | |
sentinel parallel-syncs resque 5 |
重点参数说明:
bind:服务监听地址,用于客户端连接,默认为本机地址daemonize:是否以后台 daemon(后台进程)方式运行,设为 yesprotected-mode:是否开启安全保护模式,设为 no,否则影响远程访问 / 连接port:端口,默认是 26379logfile:日志文件路径pidfile:pid 文件路径dir:工作目录sentinel monitor <master-name> <master-ip> <master-port> <quorum>:设置 Sentinel 要监控的 masterquorum:判定 master 失效(客观下线)最少需要的仲裁 Sentinel 节点数,即同意故障转移的法定投票数。例如 quorum 为 2 表示当有 2 个 sentinel 认为 master 失效时,master 才算真正失效。sentinel 定时向 master 发出 PING 包来确认 master 是否挂掉。
但网络是不可靠的,有时某个 sentinel 可能因为网络拥堵没收到 master 的响应,从而误以为 master 已挂掉。因此需要多个 sentinel 都一致认为 master 已挂,才可进行主从切换、故障转移,保证了公平性和高可用。
sentinel auth-pass <master-name> <password>:设置连接 master 服务器的密码sentinel down-after-milliseconds <master-name> <milliseconds>:指定如果 master 在多少毫秒之后没有应答 sentinel,sentinel 则主观上认为 master 下线(主观下线)sentinel parallel-syncs <master-name> <nums>:表示允许并行同步的 slave 个数,当 master 挂了后,哨兵会选出新的 master,此时,剩余的 slave 会向新的 master 发起同步数据sentinel failover-timeout <master-name> <milliseconds>:故障转移的超时时间。进行故障转移时,如果超过设置的毫秒,表示故障转移失败sentinel notification-script <master-name> <script-path>:配置当某一事件发生时所需要执行的脚本sentinel client-reconfig-script <master-name> <script-path>:客户端重新配置 master 参数脚本
# 案例演示
# 架构说明
**如果想要实现高可用,建议将哨兵 Sentinel 配置成单数,且大于等于 3 台。** 好处有二:
- 防止某台 sentinel 无法连接到 master,导致误切换
- 利于投票选举
一个最简易的 Redis Sentinel 集群如下所示(官方文档中的一个例子),其中:
- 3 个 Sentinel 节点
- 1 个 Master 节点,2 个 Slave 节点
如果 Master 出现问题,只要 Sentinel 集群其中的两个投票赞同的话,就会开始故障转移工作,从 2 个 Slave 中重新选出一个作为 master。

# 配置说明

由于机器硬件关系,我们的 3 个哨兵都同时配置进 192.168.111.169 同一台机器,即3 个哨兵和 master 在一台机器上。
配置这 3 个哨兵的配置文件:



master 配置文件说明:

# 先测试正常的主从复制
- 169 机器上新建 redis6379.conf 配置文件,由于 6379 后续可能会变成从机,需要设置访问新主机的密码,请设置 masterauth 项访问密码为 111111,不然后续可能报错 master_link_status:down
- 172 机器上新建 redis6380.conf 配置文件,设置好
replicaof \<masterip> \<masterport>,以及 masterauth 项访问密码为 111111 - 173 机器上新建 redis6381.conf 配置文件,设置好
replicaof \<masterip> \<masterport>,以及 masterauth 项访问密码为 111111 - 启动 3 台机器实例:
redis-cli -a 111111 -p 6379redis-cli -a 111111 -p 6380redis-cli -a 111111 -p 6381
- 测试
# Sentinel 来了!
sentinel 之间通过 master 来获取:
- slave 信息
- 其他 sentinel 信息
从而实现通信。
在 master(6379)这台机器上启动 3 个 sentinel(26379/26380/26381),完成监控
redis-sentinel sentinel26379.conf --sentinelredis-sentinel sentinel26380.conf --sentinelredis-sentinel sentinel26381.conf --sentinel
![image-20230808110202022]()
![image-20230808110255818]()
查看哨兵的日志文件
sentinel26379.log,可以看到当前 sentinel 的信息、所监控 master 以及 slave 的信息、其他 sentinel 的信息:![image-20230808111127304]()
再测试一次主从复制,木有问题



# 当 master 挂了!
通过命令 SHUTDOWN 手动关闭 6379 服务器,模拟 master 挂掉。
思考以下问题:
问题 1:两台 slave 上的数据还 OK!
问题 2:** 会从这两台 slave 上选出新的 master!** 具体信息可查看 sentinel 的 log 文件。
在此过程中,哨兵配置文件
sentinel.conf中会自动生成内容信息问题 3:down 机的旧 master 重启归来,也只能拜认新 master,作它的 slave!
在 master6379 宕机后,会出现两种错误:
Error:Server closed the connection
Error:Broken pipe
broken pipe:pipe 是管道的意思,管道里面是数据流,通常是从文件或网络套接字读取的数据。当该管道从另一端突然关闭时,会发生数据突然中断,即是 broken,对于 socket 来说,可能是网络被拔出或另一端的进程崩溃。
如何解决:当该异常产生的时候,对于服务端来说,并没有多少影响。因为可能是某个客户端突然中止了进程导致了该错误。
总结:这个异常是客户端读取超时关闭了连接,这时候服务器端再向客户端已经断开的连接写数据时就发生了 broken pipe 异常!
![image-20230808113740061]()

针对本次案例,分析谁是 master:
- 6381 被选为新 master,上位成功
- 以前的 6379 从 master 降级变成了 slave
- 6380 还是 slave,只不过换了个新老大 6381 (6379 变 6381),6380 还是 slave
# 对比新老 master 的配置文件
旧 master(6379)的配置文件 redis6379.conf 中会自动生成以下内容,让 其去做新 master(6381)的 slave:

新 master(6381)的配置文件 redis6381.conf 中:
- 自动删掉
replicaof参数的配置 - 自动生成以下内容:
结论:
- conf 文件的内容会被 sentinel 动态更改
- Master-Slave 切换后,master_redis.conf、slave_redis.conf 和 sentinel.conf 的内容都会发生改变,即master_redis.conf 中会多一行 slaveof 的配置,sentinel.conf 的监控目标会随之调换
# 其他备注
- 生产都是不同机房不同服务器,很少出现 Sentinel 全挂掉的情况
- 可以同时监控多个 master,一行一个
# 🌟Sentinel 原理
# 三个定时任务
Sentinel 维护着三个定时任务以监测 Redis 节点及其它 Sentinel 节点的状态:
info 任务:每个 Sentinel 每隔 10 秒就会向 Redis 集群中的每个节点发送
info命令,以获得最新的 Redis 拓扑结构。ping 任务:每个 Sentinel 每隔 1 秒就会向所有 Redis 节点及其它 Sentinel 节点发送一条
ping命令,以检测这些节点的存活状态。该任务是判断节点在线状态的重要依据。pub/sub 任务:
每个 Sentinel 节点在启动时都会向所有 Redis 节点订阅
__sentinel__:hello主题的信息,当 Redis 节点中该主题的信息发生了变化,就会立即通知到所有订阅者。 启动后,每个 Sentinel 节点每 2 秒就会向每个 Redis 节点发布一条
__sentinel__:hello主题的信息,该信息是当前 Sentinel 对每个 Redis 节点在线状态的判断结果及当前 Sentinel 节点信息。 当 Sentinel 节点接收到
__sentinel__:hello主题信息后,就会读取并解析这些信息,然后主要完成以下三项工作:- 如果发现有新的 Sentinel 节点加入,则记录下新加入 Sentinel 节点信息,并与其建立连接。
- 如果发现有 Sentinel Leader 选举的选票信息,则执行 Leader 选举过程。
- 汇总其它 Sentinel 节点对当前 Redis 节点在线状态的判断结果,作为 Redis 节点客观下线的判断依据。
# Redis 节点下线(DOWN)判断
对于每个 Redis 节点在线状态的监控是由 Sentinel 完成的。
# 主观下线(Subjectively DOWN)
每个 Sentinel 节点每秒就会向每个 Redis 节点发送 ping 心跳检测,如果 Sentinel 在 [down-after-milliseconds] 时间内没有收到某 Redis 节点的回复,则 Sentinel 节点就会对该 Redis 节点做出 “下线状态” 的判断。这个判断 **仅仅是当前 Sentinel 节点的 “一家之言”**,所以称为主观下线。

# 客观下线(Objectively DOWN)
当 Sentinel 主观下线的节点是 master 时,该 Sentinel 节点会向每个其它 Sentinel 节点发送 sentinel is-master-down-by-addr 命令,以询问其对 master 在线状态的判断结果。这些 Sentinel 节点在收到命令后会向这个发问 Sentinel 节点响应 0(在线)或 1(下线)。当 Sentinel 收到超过 quorum 个(通常为过半)下线判断后,就会对 master 做出客观下线判断。

# Sentinel Leader 选举(Raft 算法)
当 Sentinel 节点对 master 做出客观下线判断后,由 Sentinel Leader 来完成后续的故障转移。即 Sentinel 集群中的节点也并非是对等节点,是存在 Leader 与 Follower 的。
Sentinel Leader 的选举是通过 Raft 算法 实现的。Raft 算法比较复杂,后面会详细学习,这里仅简单介绍一下 **大致思路(先到先得)**:
- 每个 Sentinel 选举参与者都具有当选 Leader 的资格,当其完成了 “客观下线” 判断后,就会立即 “毛遂自荐” 推选自己做 Leader,将自己的提案发送给所有 Sentinel 参与者。
- 其它参与者在收到提案后,只要自己手中的选票没有投出去,其就会立即通过该提案,并将同意结果反馈给提案者。
- 后续再过来的提案会由于该参与者没有了选票而被拒绝。
- 当提案者收到了同意反馈数量大于等于 max (quorum, sentinelNum/2+1) 时,该提案者当选 Leader。
说明:
- 在网络没有问题的前提下,基本就是谁先做出了 “客观下线” 判断,谁就会首先发起 Sentinel Leader 的选举,谁就会得到大多数参与者的支持,谁就会当选 Leader。
- Sentinel Leader 选举在故障转移发生之前进行。
- 故障转移结束后 Sentinel 不再维护这种 Leader-Follower 关系。
# Master 选举
在进行故障转移时,Sentinel Leader 需要从所有 Redis 的 Slave 节点中选择出新的 Master。其选择算法为:
过滤掉所有主观下线的,或心跳没有响应 Sentinel 的,或 replica-priority 值为 0 的 Redis 节点
slave 优先级:在剩余 Redis 节点中选择出
replica-priority最小的的节点列表。如果只有一个节点,则直接返回,否则,继续复制进度:从优先级相同的节点列表中选择复制偏移量最大的节点。如果只有一个节点,则直接返回,否则,继续
runid(运行 id):从复制偏移值量相同的节点列表中选择runid 最小的节点返回

# 故障转移(failover)流程
集群正常运行:3 个 sentinel 监控一主二从集群,正常运行中
![image-20230808161905591]()
SDown 主观下线(Subjectively Down):指的是单个 Sentinel 实例对 master 服务器做出的下线判断(有可能是接收不到订阅,之间的网络不通等等原因)。如果 master 服务器在 [
sentinel down-after-milliseconds] 给定的毫秒数之内没有回应 PING 命令,或者返回一个错误消息,那么这个 Sentinel 会主观的 (单方面的) 认为这个 master 不可以用了。sentinel 配置文件中的
sentinel down-after-milliseconds <masterName> <timeout>设置了判断主观下线的时间长度,表示 master 被当前 sentinel 实例认定为失效的间隔时间。![image-20230808162539926]()
ODown 客观下线(Objectively Down):需要一定数量的 sentinel,多个 sentinel 达成一致意见才能认为一个 master 客观上已经宕掉。
![image-20230808162827271]()
master-name是对某个 master+slave 组合的一个区分标识 (一套 sentinel 可以监听多组 master+slave 这样的组合)quorum这个参数是进行客观下线的一个依据,即法定人数 / 法定票数。意思是至少有 quorum 个 sentinel 认为这个 master 有故障才会对这个 master 进行下线以及故障转移。因为有的时候,某个 sentinel 节点可能因为自身网络原因导致无法连接 master,而此时 master 并没有出现故障,所以这就需要多个 sentinel 都一致认为该 master 有问题,才可以进行下一步操作,这就保证了公平性和高可用。
Sentinel Leader 选举:从 sentinel 集群中选出 Sentinel Leader(兵王):当 master 被判断 ODown 以后,各个 sentinel 节点会进行协商,先通过Raft 算法选举出一个 Sentinel Leader,由它进行 failover (故障迁移)。
监视该 Master 的所有 Sentinel 都有可能被选为 Leader,选举使用的算法是 Raft 算法,其基本思路是 **先到先得**:即在一轮选举中,Sentinel A 向 Sentinel B 发送成为 Leader 的申请,如果 Sentinel B 没有同意过其他 Sentinel,则它会同意 Sentinel A 成为 Leader
![image-20230808164314705]()
从三个 sentinel 实例的 log 文件中可以看见兵王的诞生过程以及兵王执行故障迁移的过程:
![image-20230808163922904]()
sentinel26379.log ![image-20230808163958440]()
sentinel26380.log ![image-20230808164037410]()
sentinel26381.log 故障转移,选举新的 master:
新主登基:**新 master 选举算法** 如下:
优先级高:所有 slave 中,根据 redis.conf 配置文件中的优先级
slave-priority或者replica-priority,选择优先级最高的 slave 作为新 master。数字越小优先级越高
![image-20230808170206385]()
复制偏移大:所有 slave 中,根据复制偏移位置
offset,该值最大的 slave 作为新 master。Run ID 小:所有 slave 中,选择 Run ID 最小的 slave 作为新 master,是按照字典顺序,ASCII 码。
![image-20230808165640759]()
群臣俯首:一朝天子一朝臣,换个码头重新拜
- Sentinel leader 会对选举出的 slave 执行
SLAVEOF NO ONE命令,将其提拔为新 master - Sentinel leader 向其余 slave 发送
SLAVEOF命令,使它们成为新 master 的 slave
- Sentinel leader 会对选举出的 slave 执行
旧主拜服:老 master 回来也认怂
- 老 master 成为新 master 的 slave
- Sentinel leader 会让老 master 降级为 slave,并恢复正常工作
总结:上述 failover(故障迁移)均由 sentinel 独自完成,无需人工干预,因此称之为无人值守安装!








# Redis 节点上线
不同的节点类型,其上线的方式也是不同的。
# 原节点上线
无论是原下线的 master 节点还是原下线的 slave 节点,只要是原 Redis 集群中的节点上线,只需启动 Redis 即可。因为每个 Sentinel 中都保存有原来其监控的所有 Redis 节点列表,Sentinel 会定时查看这些 Redis 节点是否恢复。如果 Sentinel 查看到其已经恢复,则会命其从当前 master 进行数据同步。
不过,如果是原 master 上线,在新 master 晋升后 Sentinel Leader 会立即先将原 master 节点更新为 slave,然后才会定时查看其是否恢复。
# 新节点上线
如果需要在 Redis 集群中添加一个新的节点,其未曾出现在 Redis 集群中,则上线操作只能手工完成。即添加者在添加之前必须知道当前 master 是谁,然后在新节点启动后运行 slaveof 命令加入集群。
# Sentinel 节点上线
如果要添加的是 Sentinel 节点,无论其是否曾经出现在 Sentinel 集群中,都需要手工完成。即添加者在添加之前必须知道当前 master 是谁,然后在配置文件中修改 sentinel monitor 属性,指定要监控的 master,然后启动 Sentinel 即可。
# Sentinel 使用建议
哨兵的数量应为多个,且奇数。哨兵本身应该集群,保证高可用。
各个哨兵的配置应一致。
如果哨兵部署在 Docker 等容器里面,尤其要注意端口的正确映射。
主从复制 + 哨兵机制 **并不能确保数据零丢失**。因为从 master 挂掉到选举出新 master 的这段时间内,无法执行写命令!引出集群(cluster)
# 分布式系统 / 切片集群(cluster)
作为 Redis 实现高可用的一种方案,优于
主从复制 + Sentinel方案!
Redis 分布式系统,官方称为 Redis Cluster, Redis 集群,其是 Redis 3.0 开始推出的分布式解决方案。其可以很好地解决不同 Redis 节点存放不同数据,并将用户请求方便地路由到不同 Redis 的问题。
# 已经有主从复制、Sentinel 了,为什么还需要 Redis Cluster?
主从复制和 Redis Sentinel 这两种方案本质都是通过增加主库(master)的副本(slave)数量的方式来提高 Redis 服务的整体可用性和读吞吐量,都不支持横向扩展来缓解写压力,以及解决缓存数据量过大的问题。

通常情况下,更建议使用 **Redis 切片集群(cluster)** 这种方案,更能满足高并发场景下分布式缓存的要求。
# 是什么
简单来说就是 **部署多台 master,它们之间平等,每个 master 只存储整个数据库的一部分数据,同时对外提供读 / 写服务,实现负载均衡**。缓存的数据库相对均匀地分布在这些 Redis 实例上,客户端的请求通过 路由规则 转发到目标 master 上。
为了保障集群整体的高可用,我们需要保证集群中每一个 master 的高可用,可以通过主从复制给每个 master 配置一个或者多个从节点(slave)。

Redis 切片集群对于横向扩展非常友好,只需要增加 Redis 节点到集群中即可。
# 作用
Redis Cluster 的功能总结如下:
- 支持多个 Master,每个 Master 又可以挂载多个 Slave。
- 读写分离
- 支持数据的高可用
- 支持海量数据的读写存储操作
- 自带故障转移(failover)机制,内置了高可用的支持,无需再去使用哨兵功能。
- 客户端只需连接集群中的任意一个可用 Master 节点即可,不需要连接集群中的所有 Master 节点。
- 槽位 slot负责分配到各个物理服务节点,由对应的集群来负责维护 Redis 节点、插槽、数据之间的关系。
Redis Cluster 通过 分片(Sharding) 来进行数据管理,提供 主从复制(Master-Slave Replication)、故障转移(Failover) 等开箱即用的功能,可以非常方便地帮助我们解决 Redis 大数据量缓存以及 Redis 服务高可用的问题。
Redis Cluster 这种方案可以很方便地进行 横向拓展(Scale Out),内置了开箱即用的解决方案。当 Redis Cluster 的处理能力达到瓶颈无法满足系统要求的时候,直接动态添加 Redis 节点到集群中即可。根据官方文档中的介绍,Redis Cluster 支持扩展到 1000 个节点。反之,当 Redis Cluster 的处理能力远远满足系统要求,同样可以动态删除集群中 Redis 节点,节省资源。

可以说,Redis Cluster 的动态扩容和缩容是其最大的优势。
# 最基本架构
为了保证高可用,Redis Cluster 至少需要 3 个 master 以及 3 个 slave,也就是说每个 master 必须至少有 1 个 slave。master 和 slave 之间做主从复制,slave 会实时同步 master 上的数据。
不同于普通的 Redis 主从架构,这里的 slave 不对外提供读服务,主要用来保障 master 的高可用,当 master 出现故障的时候替代它。

如果 master 只有一个 slave 的话,master 宕机之后就直接使用这个 slave 替代 master 继续提供服务,保证 Redis Cluster 的高可用。
如果 master 有多个 slave 的话,Redis Cluster 中的其他节点会从这个 master 的所有 slave 中选出一个替代 master 继续提供服务。Redis Cluster 总是希望数据最完整的 slave 被提升为新的 master。
Redis Cluster 是去中心化的(各个节点基于 Gossip 进行通信),任何一个 master 出现故障,其它的 master 节点不受影响,因为 key 找的是 **哈希槽(hash slot)** 而不是 Redis 节点。不过,Redis Cluster 至少要保证宕机的 master 有一个 slave 可用。
如果宕机的 master 无 slave 的话,为了保障集群的完整性,保证所有的哈希槽都指派给了可用的 master,整个集群将不可用。这种情况下,还是想让集群保持可用的话,可以将 cluster-require-full-coverage 这个参数设置成 no,该参数表示需要 16384 个 slot 都正常被分配时 Redis Cluster 才可以对外提供服务。
如果想要添加新的 master 节点,只需要重新分配 hash slot 即可。

如果想要移除某个 master 节点,需要先将该节点的 hash slot 移动到其他节点上,这样才可以进行删除,不然会报错。
# 🌟数据分片算法
类似的问题:
Redis Cluster 是如何分片的?
Redis Cluster 中的数据是如何分布的?
如何确定给定 key 应该分布到哪个哈希槽中?
常见的数据分区规则有两大类:
顺序分区:将数据按照某种顺序平均分配到不同的节点。不同的顺序方式,产生了不同的分区算法。
- 轮询:每产生一个数据,就依次分配到不同的节点。其分配的结果是,在数据总量非常庞大的情况下,每个节点中数据是很平均的。但生产者与数据节点间的连接要长时间保持。
- 时间片轮转:在某固定长度的时间片内的数据都会分配到同一个节点。时间片结束,再产生的数据就会被分配到下一个节点。可能会出现节点数据不平均的情况(因为每个时间片内产生的数据量可能是不同的)。但生产者与节点间的连接只需占用当前正在使用的这个就可以,其它连接使用完毕后就立即释放。
- 数据块:在整体数据总量确定的情况下,根据各个节点的存储能力,可以将连接的某一整块数据分配到某一节点。
- 业务主题:数据可根据不同的业务主题,分配到不同的节点。
哈希分区:充分利用数据的哈希值来完成分配,对数据哈希值的不同使用方式产生了不同的哈希分区算法。
哈希取余
一致性哈希
哈希槽
Redis Cluster 采取的数据分片算法就是这种!
这里仅展开介绍上述三种哈希分区算法!
# 哈希取余 分区算法
小厂可用

该算法的前提是,每个节点都已分配好了一个唯一序号,对于 N 个节点的集群,其序号范围为 [0, N-1]。选取数据本身或可以代表数据特征的数据的一部分作为 key,计算 hash (key) 与节点数量 N 的模,即 hash(key) % N ,计算结果决定了该数据的存储节点的序号。
优点:
- 简单有效。只需要预估好数据规模,规划好节点,就能保证一段时间的数据支撑。
- 负载均衡。使用 Hash 算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息)。
缺点:
- Redis 节点的扩容 / 缩容麻烦。已经存储过的数据需要根据新的节点数量 N 进行数据迁移,否则用户根据 key 是无法再找到原来的数据的。生产中扩容一般采用翻倍扩容方式,以减少扩容时数据迁移的比例。
- 某个 Redis 机器宕机了,由于台数数量变化,会导致 hash 取余全部数据重新洗牌。
# 一致性哈希 分区算法
在哈希取余算法的基础上,固定了取余的分母为 232-1(因此称之一致性),而不再是 Master 节点数量。
# 设计思想
为了解决哈希取余分区算法中的数据变动和映射问题(某个机器宕机导致分母数量改变了,自然取余数不 OK 了)。目的是当 Redis 节点个数发生变动时,尽量减少客户端到服务器的映射关系的影响。
一致性哈希算法通过一个叫作 **一致性哈希环的数据结构实现。这个环的起点是 0,终点是 232 - 1,并且起点与终点重合。环中间的整数按逆 / 顺时针分布,故这个环的整数分布范围是[0, 232-1]**。

上图中存在四个对象 o0、 o1、 o2、 o3,分别代表四个待分配的数据,红色方块是这四个数据的 hash (o) 在 Hash 环中的落点。同时,图上还存在三个节点 m0、 m1、 m2,绿色圆圈是这三节点的 hash (m) 在 Hash 环中的落点。
现在要为数据分配其要存储的节点。该数据对象的 hash (o) 按照逆 / 顺时针方向距离哪个节点的 hash (m) 最近,就将该数据存储在哪个节点。这样就会形成上图所示的分配结果。
# 3 大步骤
构建一致性哈希环:
一致性哈希算法必然有个 hash 函数用于产生 hash 值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个 **hash 空间 [0,232-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连 (0 = 232)**,这样让它形成了一个逻辑上的环形空间。
它也是按照使用取模的方法,前面介绍的是对 Redis 节点的数量进行取模。而 **一致性哈希算法是对 232 取模(因为取余的分母是固定的,所以称其一致性)**。
简单来说,一致性 Hash 算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数的值空间为 [0,232-1](即哈希值是一个 32 位无符号整形),整个哈希环如下图:整个空间按顺时针方向组织,圆环的正上方的点代表 0,0 点右侧的第一个点代表 1,以此类推,2、3、4、…… 直到 232-1,也就是说0 点左侧的第一个点代表 232-1, 0 和 232-1 在零点中方向重合,我们把这个 **由 232 个点组成** 的圆环称为
Hash环。![image-20230809010605612]()
Redis 服务器节点 IP 映射:
将集群中各个 Redis 节点的 IP 映射到环上的某一个位置。
将各个 Redis 服务器的 IP 或主机名作为关键字使用 Hash 进行哈希,这样每台机器就能确定其在哈希环上的位置。假如 4 个 Redis 节点 NodeA、NodeB、NodeC、NodeD,经过IP 地址的哈希函数计算 hash (ip),使用 IP 地址哈希后在环空间的位置如下:
![image-20230809114247849]()
落 key 规则:
当我们需要存储一个键值对时,首先计算 key 的 hash 值,hash (key),确定此数据在环上的位置,从此位置沿环 **顺时针**“行走”,第一台遇到的 Redis 服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有 Object A、Object B、Object C、Object D 四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性 Hash 算法,Object A 会被定为到 Node A 上,Object B 被定为到 Node B 上,Object C 被定为到 Node C 上,Object D 被定为到 Node D 上。
![image-20230809114625589]()



# 优缺点
优点:
容错性
假设 Node C 宕机,可以看到此时对象 A、B、D 不会受到影响。一般的,在一致性 Hash 算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是 C 挂了,受到影响的只是 B、C 之间的数据,且这些数据会转移到 D 进行存储。
![image-20230809115305990]()
Redis 节点的扩容 / 缩容方便
随着数据量的增加,需要增加一台节点 NodeX,位置在 A 和 B 之间,那受到影响的也就是 A 到 X 之间的数据,重新把 A 到 X 的数据录入到 X 上即可,不会导致 hash 取余全部数据重新洗牌。
![image-20230809120153493]()


缺点:数据倾斜问题
当 Redis 服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的数据对象大部分集中缓存在某一台服务器上)问题。
例如系统中只有两台服务器:

# 🌟哈希槽 (slot) 分区算法
大厂都用它!而且 Redis Cluster 的数据分区采用的就是这种方式!
# 设计思想(JavaGuide)
Redis Cluster 并没有使用一致性哈希,采用的是 **哈希槽分区** ,每一个键值对都属于一个 hash slot(哈希槽)。
Redis Cluster 通常有 16384 个哈希槽 ,要计算给定 key 应该分布到哪个哈希槽中,我们只需要先对每个 key 计算 CRC-16(XMODEM) 校验码,然后再对这个校验码对 16384 (哈希槽的总数) 取模,得到的值即是 key 对应的哈希槽。
哈希槽的计算公式如下:
HASH_SLOT = CRC16(key) mod 16384
创建并初始化 Redis Cluster 的时候,Redis 会自动平均分配这 16384 个哈希槽到各个节点,不需要我们手动分配。如果你想自己手动调整的话,Redis Cluster 也内置了相关的命令比如 ADDSLOTS、ADDSLOTSRANGE (后面会详细介绍到重新分配哈希槽相关的命令)。
客户端连接 Redis Cluster 中任意一个 master 节点即可访问 Redis Cluster 的数据。当客户端发送命令请求的时候,需要先根据 key 通过上面的计算公示找到的对应的哈希槽,然后再查询哈希槽和节点的映射关系,即可找到目标节点。

如果哈希槽确实是当前节点负责,那就直接响应客户端的请求返回结果,如果不由当前节点负责,就会返回 -MOVED 重定向错误,告知客户端当前哈希槽是由哪个节点负责,客户端向目标节点发送请求并更新缓存的哈希槽分配信息。

这个时候你可能就会疑问:为什么还会存在找错节点的情况呢?根据公式计算难道还会出错?
这是因为 Redis Cluster 内部可能会重新分配哈希槽,比如扩容缩容的时候(后文中有详细介绍到 Redis Cluster 的扩容和缩容问题),这就可能会导致客户端缓存的哈希槽分配信息会有误。
从上面的介绍中,我们可以简单总结出 Redis Cluster 哈希槽分区机制的优点:解耦了数据和节点之间的关系,提升了集群的横向扩展性和容错性。
# 设计思想
为了解决数据分配不均匀的问题(数据倾斜),哈希槽分区算法在数据和 Redis 节点之间加了一层哈希槽(slot),用于管理数据和 Redis 节点之间的关系,相当于是把数据放入槽中,再把槽映射到 Redis 节点上。

该算法 **首先虚拟出一个固定数量为 214=16384 的整数集合,其中每个整数称为一个槽(slot)。这个槽的数量一般是远远大于节点数量的。然后再将所有槽平均映射到各个 Redis 节点之上**。
例如,Redis 分布式系统中共虚拟了 16384(即 214) 个 slot 槽,其范围为 [0, 16383]。假设共有 3 个节点,那么 slot 槽与节点间的映射关系如下图所示:

数据只与 slot 槽有关系,与 Redis 节点没有直接关系。数据根据计算公式 slot = hash(key) % slotNums 映射到 slot 槽。这也是该算法的一个优点,解耦了数据与节点,客户端无需维护节点,只需维护与 slot 槽的关系即可。
Redis Cluster 的数据分区采用的就是该算法。其计算槽点的公式为: slot = CRC16(key) % 16384 。 CRC16 () 是一种带有校验功能的、具有良好分散功能的、特殊的 hash 算法函数。 其实 Redis 中计算槽点的公式不是上面的那个,而是: slot = CRC16(key) & 16383 。
若要计算 a % b,如果 b 是 2 的整数次幂,那么 a % b = a & (b-1)。
# 为什么哈希槽的数量是 16384 个?
CRC16 () 算法产生的哈希值有 16bit,即 216=65536 个值,为什么 Redis 集群的算法只采用 214=16384 个哈希槽?在进行 mode 运算时,为什么是
HASH_SLOT = CRC16(key) mod 16384而不是HASH_SLOT = CRC16(key) mod 65536?
作者的回复:

消息头 clusterMsg 的结构:

标准回答:
正常的心跳包会携带一个节点的完整配置,它会以幂等的方式更新旧的配置,这意味着心跳包会附带当前节点的负责的哈希槽的信息。假设哈希槽采用 16384,则占空间 2k(16384/8)。假设哈希槽采用 65536,则占空间 8k (65536/8),这是令人难以接受的内存占用。因此,如果槽位为 65536,那么发送心跳信息的消息头大小达到 8k,发送的心跳包过于庞大,浪费带宽。
在消息头中最占空间的是
myslots[CLUSTER_SLOTS/8]:- 当槽位为 65536 时,这块的大小是: 65536÷8÷1024=8kb
- 当槽位为 16384 时,这块的大小是: 16384÷8÷1024=2kb
因为每秒钟 redis 节点需要发送一定数量的 ping 消息作为心跳包,如果槽位为 65536,这个 ping 消息的消息头太大了,浪费带宽。
对于基本不可能超过 1000 个 master 节点数量的 redi 集群而言,16384 个槽位就已经够用了。
集群的节点越多,心跳包的消息体内携带的数据越多。如果节点过 1000 个,也会导致网络拥堵。因此 redis 作者不建议 redis cluster 节点数量超过 1000 个。那么,对于节点数在 1000 以内的 redis cluster 集群,16384 个槽位够用了。没有必要拓展到 65536 个。
槽位越小,节点少的情况下,压缩比高,容易传输
Redis 的 master 节点的配置信息中它所负责的哈希槽是通过一张 bitmap 的形式来保存的,在传输过程中会对 bitmap 进行压缩,但是如果 bitmap 的填充率 slots / N 很高的话 (N 表示节点数),bitmap 的压缩率就很低。如果节点数很少,而哈希槽数量很多的话,bitmap 的压缩率就很低。
# 集群操作(案例演示)
# 集群架构说明
集群的架构是最简单的三主三从。即在 3 台虚拟机上新建 6 个独立的 Redis 实例服务,每台机器上一主一从,设计图如下:
注意:master 与 slave 的角色以及配对关系,实际上是在系统搭建成功后自动随机分配的。
.JPEG)
# 集群搭建
接下来的操作中,Redis 节点从 6381~6386 变成了 6380~6385。
# 集群架构
下面要搭建的 Redis 分布式系统由 6 个节点构成,这 6 个节点的地址及角色分别如下表所示。一个 master 配备一个 slave,不过 master 与 slave 的角色以及配对关系,实际上是在系统搭建成功后自动随机分配的。

# 删除持久化文件
先将之前 “Redis 主从集群” 中在 Redis 安装目录下生成的 RDB 持久化文件 dump638*.conf 与 AOF 持久化文件删除。因为 Redis 分布式系统要求创建在一个空的数据库之上。注意, AOF 持久化文件全部在 appendonlydir 目录中。

# 创建目录
在 Redis 安装目录中 mkdir 一个新的目录 cluster-dis,用作分布式系统的工作目录。
# 复制 2 个配置文件
将 cluster 目录中的 redis.conf 与 redis6380.conf 文件复制到 cluster-dis 目录。

# 修改 redis.conf
对于 redis.conf 配置文件,主要涉及到以下三个四个属性:
dir:指定工作目录为前面创建的 cluster-dis 目录。持久化文件、节点配置文件将来都会在工作目录中自动生成。![image-20231213190633688]()
cluster-enabled:开启 Redis 的集群模式。![image-20231213190642530]()
cluster-config-file:指定 “集群节点” 的配置文件。该文件会在第一次节点启动时自动生成,其生成的路径是在 dir 属性指定的工作目录中。在集群节点信息发生变化后(如节点下线、故障转移等),节点会自动将集群状态信息保存到该配置文件中。不过,该属性在这里仍保持注释状态。在后面的每个节点单独的配置文件中配置它。![image-20231213190827903]()
cluster-node-timeout:指定 “集群节点” 间通信的超时时间阈值,单位毫秒。![image-20231213190925419]()




# 修改 redis6380.conf
仅添加一个 cluster-config-file 属性即可。

# 复制 5 个配置文件
使用 redis6380.conf 复制出 5 个配置文件 redis6381.conf、redis6382.conf、redis6383.conf、redis6384.conf、 redis6385.conf。

cluster-dis 中出现了 7 个配置文件。

# 修改 5 个配置文件
修改 5 个配置文件 redis6381.conf、 redis6382.conf、 redis6383.conf、 redis6384.conf、redis6385.conf 的内容,将其中所有涉及的端口号全部替换为当前文件名称中的端口号。例如,下面的是 redis6381.conf 的配置文件内容。

# 集群启动与关闭
# 启动节点
启动所有 Redis 节点。


此时查看 cluster-dis 目录,可以看到生成了 6 个 nodes 的配置文件。

# 创建集群
6 个节点启动后,它们仍是 6 个独立的 Redis,通过 redis-cli --cluster create 命令可将 6 个节点创建了一个分布式系统。

该命令用于将指定的 6 个节点连接为一个分布式系统。 --cluster replicas 1 指定每个 master 会带有一个 slave 作为副本。
回车后会立即看到如下日志:

输入 yes 后回车,系统就会将以上显示的动态配置信息真正的应用到节点上,然后就可看到如下日志:

# 测试集群

通过 cluster nodes 命令可以查看系统中各节点的关系及连接情况。只要能看到每个节点给出 connected,就说明分布式系统已经成功搭建。不过,对于客户端连接命令 redis-cli,需要注意两点:
- 参数 - c:表示这是要连接一个 “集群”,而非是一个节点。
- 端口号:可以使用 6 个中的任意一个。
# 关闭集群
对于分布式系统的关闭,只需将各个节点 shutdown 即可。

# 连接集群
无论要怎样操作分布式系统,都需要首先连接上。

与之前单机连接相比的唯一区别就是增加了参数 - c。
# 写入数据
# key 单个写入
无论 value 类型为 String 还是 List、Set 等集合类型,只要写入时操作的是一个 key,那么在分布式系统中就没有问题。例如:


# key 批量操作
对一次写入多个 key 的操作,由于多个 key 会计算出多个 slot,多个 slot 可能会对应多个节点。而由于一次只能写入一个节点,所以该操作会报错。

不过,系统也提供了一种对批量 key 的操作方案,为这些 key 指定一个统一的 group,让这个 group 作为计算 slot 的唯一值。

# 集群查询
# 查询 key 的 slot
通过 cluster keyslot 可以查询指定 key 的 slot。例如,下面是查询 emp 的 slot。

# 查询 slot 中 key 的数量
通过 cluster countkeysinslot 命令可以查看到指定 slot 所包含的 key 的个数。

# 查询 slot 中的 key
通过 cluster getkeysinslot 命令可以查看到指定 slot 所包含的 key。

# 故障转移(failover)
# 模拟故障
通过 cluster nodes 命令可以查看集群的整体架构及连接情况。

当然,也可以通过 info replication 查看当前客户端连接的节点的角色。可以看到,6381 节点是 master,其 slave 为 6383 节点。

为了模拟 6381 宕机,直接将其 shutdown。

通过客户端连接上 6383 节点后可以查看到,6383 节点已经自动晋升为了 master。

重启 6381 节点后查看其角色,发现 6381 节点自动成为了 6383 节点的 slave。

# 全覆盖需求
如果某 slot 范围对应节点的 master 与 slave 全部宕机,那么整个分布式系统是否还可以对外提供读服务,就取决于属性 cluster-require-full-coverage 的设置。

该属性有两种取值:
- yes:默认值。要求所有 slot 节点必须全覆盖的情况下系统才能运行。
- no:slot 节点不全的情况下系统也可以提供查询服务。
# 集群扩容
下面要在正在运行的分布式系统中添加两个新的节点:端口号为 6386 的节点为 master 节点,其下会有一个端口号为 6387 的 slave 节点。
# 复制并修改 2 个配置文件
使用 redis6380.conf 复制出 2 个配置文件 redis6386.conf 与 redis6387.conf,并修改其中的各处端口号为相应端口号,为集群扩容做前期准备。
# 启动系统与 2 个节点
由于要演示的是在分布式系统运行期间的动态扩容,所以这里先启动分布式系统。

要添加的两个节点是两个 Redis,所以需要先将它们启动。只不过,在没有添加到分布式系统之前,它们两个是孤立节点,每个节点与其它任何节点都没有关系。

# 添加 master 节点

通过命令 redis-cli --cluster add-node {newHost}:{newPort} {existHost}:{existPort} 可以将新的节点添加到系统中。其中 {newHost}:{newPort} 是新添加节点的地址,{existHost}:{existPort} 是原系统中的任意节点地址。
添加成功后可看到如下日志。

添加成功后,通过 redis-cli -c -p 6386 cluster nodes 命令可以看到其它 master 节点都分配有 slot,只有新添加的 master 还没有相应的 slot。当然,通过该命令也可以看到该新节点的动态 ID。

# 分配 slot
为新的 master 分配的 slot 来自于其它节点,总 slot 数量并不会改变。所以 slot 分配过程本质是一个 slot 的移动过程。
通过 redis-cli –c --cluster reshard {existIP}:{existPort} 命令可 **开启 slot 分配流程**。其中地址 {existIP}:{existPort} 为分布式系统中的任意节点地址。

该流程中会首先查询出当前节点的 slot 分配情况。

然后开始 Q&A 交互。一共询问了四个问题,这里有三个:
- 准备移动多少 slot?
- 准备由谁来接收移动的 slot?
- 选择要移动 slot 的源节点,有两种方案。
- 如果选择键入 all,则所有已存在 slot 的节点都将作为 slot 源节点,即该方案将进行一次 slot 全局大分配。
- 也可以选择其它部分节点作为 slot 源节点。此时将源节点的动态 ID 复制到这里,每个 ID 键入完毕后回车,然后再复制下一个 slot 源节点动态 ID,直至最后一个键入完毕回车后再键入 done。
这里键入的是 all,进行全局大分配。

其首先会检测指定的 slot 源节点的数据,然后制定出 reshard 的方案。

这里会再进行一次 Q&A 交互,询问是否想继续处理推荐的方案。键入 yes,然后开始真正的全局分配,直至完成。

此时再通过 redis-cli -c -p 6386 cluster nodes 命令查看节点信息,可以看到 6386 节点中已经分配了 slot,只不过分配的 slot 编号并不连续。 master 节点新增完成。

# 添加 slave 节点
现要将 6387 节点添加为 6386 节点的 slave。 当然,首先要确保 6387 节点的 Redis 是启动状态。
通过 redis-cli --cluster add-node {newHost}:{newPort} {existHost}:{existPort} --cluster-slave --cluster-master-id masterID 命令可将新添加的节点直接添加为指定 master 的 slave。

回车后可看到如下的日志,说明添加成功。

此时再通过 redis-cli -c -p 6386 cluster nodes 命令可以看到其已经添加成功,且为指定 master 的 slave。

# 集群缩容
下面要将 slave 节点 6387 与 master 节点 6386 从分布式系统中删除。
# 删除 slave 节点
对于 slave 节点,可以直接通过 redis-cli --cluster del-node <delHost>:<delPort> delNodeID 命令删除。

此时再查看集群,发现已经没有了 6387 节点。

# 移出 master 的 slot
在删除一个 master 之前,必须要保证该 master 上没有分配有 slot,否则无法删除。所以,在删除一个 master 之前,需要先将其上分配的 slot 移出。

以上交互指定的是将 6386 节点中的 1999 个 slot 移动到 6380 节点。
注意:
- 要删除的节点所包含的 slot 数量在前面检测结果中都是可以看到的,例如, 6386 中的并不是 2000 个,而是 1999 个
- What is the receiving node ID?仅能指定一个接收节点
回车后继续。


此时再查看发现,6386 节点中已经没有 slot 了。

# 删除 master 节点
此时就可以删除 6386 节点了。

此时再查看集群,发现已经没有了 6386 节点。

# 局限性
Redis Cluster 存在一些使用限制:
- 仅支持 0 号数据库
- 批量 key 操作支持有限
- 分区仅限于 key
- 事务支持有限
- 不支持分级管理
# Redis Cluster 在扩容 / 缩容期间可以提供服务吗?
Redis Cluster 扩容和缩容本质是进行重新分片,动态迁移哈希槽。
为了保证 Redis Cluster 在扩容和缩容期间依然能够对外正常提供服务,Redis Cluster 提供了重定向机制,两种不同的类型:
- ASK 重定向
- MOVED 重定向
从客户端的角度来看,ASK 重定向是下面这样的:
- 客户端发送请求命令,如果请求的 key 对应的哈希槽还在当前节点的话,就直接响应客户端的请求。
- 如果客户端请求的 key 对应的哈希槽当前正在迁移至新的节点,就会返回
-ASK重定向错误,告知客户端要将请求发送到哈希槽被迁移到的目标节点。 - 客户端收到 -ASK 重定向错误后,将会临时(一次性)重定向,自动向目标节点发送一条 ASKING 命令。也就是说,接收到 ASKING 命令的节点会强制执行一次请求,下次再来需要重新提前发送 ASKING 命令。
- 客户端发送真正的请求命令。
- ASK 重定向并不会同步更新客户端缓存的哈希槽分配信息,也就是说,客户端对正在迁移的相同哈希槽的请求依然会发送到原节点而不是目标节点。

如果客户端请求的 key 对应的哈希槽已经迁移完成的话,就会返回 -MOVED 重定向错误,告知客户端当前哈希槽是由哪个节点负责,客户端向目标节点发送请求并更新缓存的哈希槽分配信息。
# CAP 定理
# 概念
CAP 定理指的是 **在一个分布式系统中,一致性(C)、可用性(A)、分区容错性(P)三者不可兼得**。
- 一致性(Consistency):分布式系统中多个主机之间是否能够保持数据一致的特性。即,当系统数据发生更新操作后,各个主机中的数据仍然处于一致的状态。
- 可用性(Availability):系统提供的服务必须一直处于可用的状态,即对于用户的每一个请求,系统总是可以在有限的时间内对用户做出响应。
- 分区容错性(Partition tolerance):分布式系统在遇到任何网络分区故障时,仍能够保证对外提供满足一致性和可用性的服务。
# 定理
CAP 定理的内容是:对于分布式系统,网络环境相对是不可控的,出现网络分区是不可避免的,因此系统必须具备分区容错性。但 **系统不能同时保证一致性(C)与可用性(A)。即要么 CP,要么 AP**。
# BASE 理论
BASE 是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的结论,是基于 CAP 定理逐步演化而来的,由以下三个短语的简写组成:
BasicallyAvailable(基本可用):分布式系统在出现不可预知故障的时候,允许损失部分可用性Soft state(软状态):允许系统数据存在的中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统主机间进行数据同步的过程存在一定延时。软状态,其实就是一种灰度状态,过渡状态。Eventually consistent(最终一致性):强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要保证系统数据的实时一致性。
BASE 理论的核心思想是:即使无法做到强一致性,但每个系统都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
# CAP 应用
# Zookeeper:CP 模式
Zookeeper 遵循的是 CP 模式,即保证了一致性(C),但牺牲了可用性(A)。当 Leader 节点中的数据发生了变化后,在 Follower 还没有同步完成之前,整个 Zookeeper 集群是不对外提供服务的。如果此时有客户端来访问数据,则客户端会因访问超时而发生重试。不过,由于 Leader 的选举非常快,所以这种重试对于用户来说几乎是感知不到的。所以说,Zookeeper 保证了一致性,但牺牲了可用性。
# Consul:CP 模式
# Redis:AP 模式
Redis 遵循的是 AP 模式,即保证了可用性(A),但牺牲了一致性(C)。
# Eureka:AP 模式
# Nacos:AP 模式
Nacos 在做注册中心时,默认是 AP 的。但其也支持 CP 模式,但需要用户提交请求进行转换。
# 使用规范
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
- 使用连接池:避免频繁创建关闭客户端连接。
- 尽量不使用 O (n) 指令,使用 O (n) 命令时要关注 n 的数量:像
KEYS *、HGETALL、LRANGE、SMEMBERS、SINTER/SUNION/SDIFF等 O (n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用HSCAN、SSCAN、ZSCAN代替。 - 使用批量操作,减少网络传输:原生批量操作命令(比如
MGET、MSET等等)、pipeline、Lua 脚本。 - 尽量不用 Redis 事务,用 Lua 脚本代替:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
- 禁止长时间开启 monitor:对性能影响比较大。
- 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
- ……
相关文章推荐:阿里云 Redis 开发规范。